ABRIL 2023
Stability AI lanza el primero de su conjunto de modelos de lenguaje StableLMhttps://stability.ai/blog/stability-ai- ... age-modelsStability AI lanzó un nuevo modelo de lenguaje de código abierto, StableLM. La versión Alpha del modelo está disponible en 3 mil millones y 7 mil millones de parámetros, con 15 mil millones a 65 mil millones de modelos de parámetros a continuación. Los desarrolladores pueden inspeccionar, usar y adaptar libremente nuestros modelos base StableLM con fines comerciales o de investigación, sujeto a los términos de la licencia CC BY-SA-4.0.
En 2022, Stability AI impulsó el lanzamiento público de Stable Diffusion, un modelo de imagen revolucionario que representa una alternativa transparente, abierta y escalable a la IA propietaria. Con el lanzamiento del conjunto de modelos StableLM, Stability AI continúa haciendo que la tecnología fundamental de IA sea accesible para todos. Nuestros modelos StableLM pueden generar texto y código y potenciarán una gama de aplicaciones posteriores. Demuestran cómo los modelos pequeños y eficientes pueden ofrecer un alto rendimiento con la formación adecuada.
El lanzamiento de StableLM se basa en nuestra experiencia en modelos de idioma anteriores de código abierto con EleutherAI, un centro de investigación sin fines de lucro. Estos modelos de lenguaje incluyen GPT-J, GPT-NeoX y la suite Pythia, que se entrenaron en el conjunto de datos de código abierto The Pile. Muchos modelos de lenguaje de código abierto recientes continúan basándose en estos esfuerzos, incluidos Cerebras-GPT y Dolly-2.
StableLM está entrenado en un nuevo conjunto de datos experimentales creado en The Pile, pero tres veces más grande con 1,5 billones de tokens de contenido. Publicaremos detalles sobre el conjunto de datos a su debido tiempo. La riqueza de este conjunto de datos otorga a StableLM un rendimiento sorprendentemente alto en tareas de conversación y codificación, a pesar de su pequeño tamaño de 3 a 7 mil millones de parámetros (en comparación, GPT-3 tiene 175 mil millones de parámetros).
También estamos lanzando un conjunto de modelos de investigación que son instrucción afinada. Inicialmente, estos modelos perfeccionados utilizarán una combinación de cinco conjuntos de datos de código abierto recientes para agentes conversacionales: Alpaca, GPT4All, Dolly, ShareGPT y HH. Estos modelos ajustados están destinados únicamente para uso en investigación y se publican bajo una licencia CC BY-NC-SA 4.0 no comercial, en línea con la licencia Alpaca de Stanford.
Vea algunos ejemplos a continuación, producidos por nuestro modelo ajustado de 7 mil millones de parámetros:
Los modelos lingüísticos formarán la columna vertebral de nuestra economía digital y queremos que todos tengan voz en su diseño. Modelos como StableLM demuestran nuestro compromiso con la tecnología de IA que es transparente, accesible y de apoyo:
Transparente. Abrimos nuestros modelos para promover la transparencia y fomentar la confianza. Los investigadores pueden "mirar debajo del capó" para verificar el rendimiento, trabajar en técnicas de interpretación, identificar riesgos potenciales y ayudar a desarrollar salvaguardas. Las organizaciones de los sectores público y privado pueden adaptar ("afinar") estos modelos de código abierto para sus propias aplicaciones sin compartir sus datos confidenciales ni ceder el control de sus capacidades de IA.
Accesible. Diseñamos para el borde para que los usuarios cotidianos puedan ejecutar nuestros modelos en dispositivos locales. Con estos modelos, los desarrolladores pueden crear aplicaciones independientes compatibles con hardware ampliamente disponible en lugar de depender de los servicios propietarios de una o dos empresas. De esta forma, los beneficios económicos de la IA son compartidos por una amplia comunidad de usuarios y desarrolladores. El acceso abierto y detallado a nuestros modelos permite a la amplia comunidad académica y de investigación desarrollar técnicas de interpretación y seguridad más allá de lo que es posible con modelos cerrados.
Apoyo. Construimos modelos para apoyar a nuestros usuarios, no para reemplazarlos. Estamos enfocados en un rendimiento de IA eficiente, especializado y práctico, no en una búsqueda de inteligencia divina. Desarrollamos herramientas que ayudan a las personas y las empresas cotidianas a utilizar la IA para desbloquear la creatividad, aumentar su productividad y abrir nuevas oportunidades económicas.
Los modelos ya están disponibles en nuestro repositorio de GitHub. Publicaremos un informe técnico completo en un futuro cercano y esperamos una colaboración continua con los desarrolladores e investigadores a medida que implementamos la suite StableLM. Además, iniciaremos nuestro programa RLHF de fuente abierta y trabajaremos con esfuerzos comunitarios como Open Assistant para crear un conjunto de datos de fuente abierta para asistentes de IA.
Pronto lanzaremos más modelos y nuestro equipo está creciendo. Si le apasiona democratizar el acceso a esta tecnología y tiene experiencia en LLM, ¡solicite aquí!
Stability AI lanza StableVicuna, el primer chatbot RLHF LLM de código abierto del mundo de IA
https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
En los últimos meses, ha habido un impulso significativo en el desarrollo y lanzamiento de chatbots. Desde el chatbot de Character.ai la primavera pasada hasta ChatGPT en noviembre y Bard en diciembre, la experiencia del usuario creada al ajustar los modelos de lenguaje para el chat ha sido un tema candente. La aparición de alternativas de acceso abierto y código abierto ha alimentado aún más este interés.
El entorno actual de los chatbots de código abierto
El éxito de estos modelos de chat se debe a dos paradigmas de formación: el ajuste fino de la instrucción y el aprendizaje reforzado a través de la retroalimentación humana (RLHF). Si bien se han realizado esfuerzos significativos para crear marcos de código abierto para ayudar a entrenar este tipo de modelos, como trlX, trl, DeepSpeed Chat y ColossalAI, hay una falta de acceso abierto y modelos de código abierto que tengan ambos paradigmas aplicados. En la mayoría de los modelos, el ajuste fino de instrucciones se aplica sin entrenamiento RLHF debido a la complejidad que implica.
Recientemente, Open Assistant, Anthropic y Stanford han comenzado a hacer que los conjuntos de datos de chat RLHF estén disponibles para el público. Esos conjuntos de datos, combinados con el entrenamiento sencillo de RLHF proporcionado por trlX, son la columna vertebral para el primer modelo de RLHF y sintonizado con aletas de instrucción a gran escala que presentamos aquí hoy: StableVicuna.
Presentamos el primer chatbot RLHF LLM de código abierto a gran escala
Estamos orgullosos de presentar StableVicuna, el primer chatbot de código abierto a gran escala entrenado a través del aprendizaje reforzado a partir de la retroalimentación humana (RLHF). StableVicuna es una versión de Vicuna v0 13b capacitada en RLHF y afinada con instrucciones adicionales, que es un modelo LLaMA 13b afinado con instrucciones. Para el lector interesado, puede encontrar más sobre Vicuña aquí.
Estos son algunos de los ejemplos con nuestro Chatbot,
Pídele que haga matemáticas básicas.
Pídele que escriba código
Pídele que te ayude con la gramática.
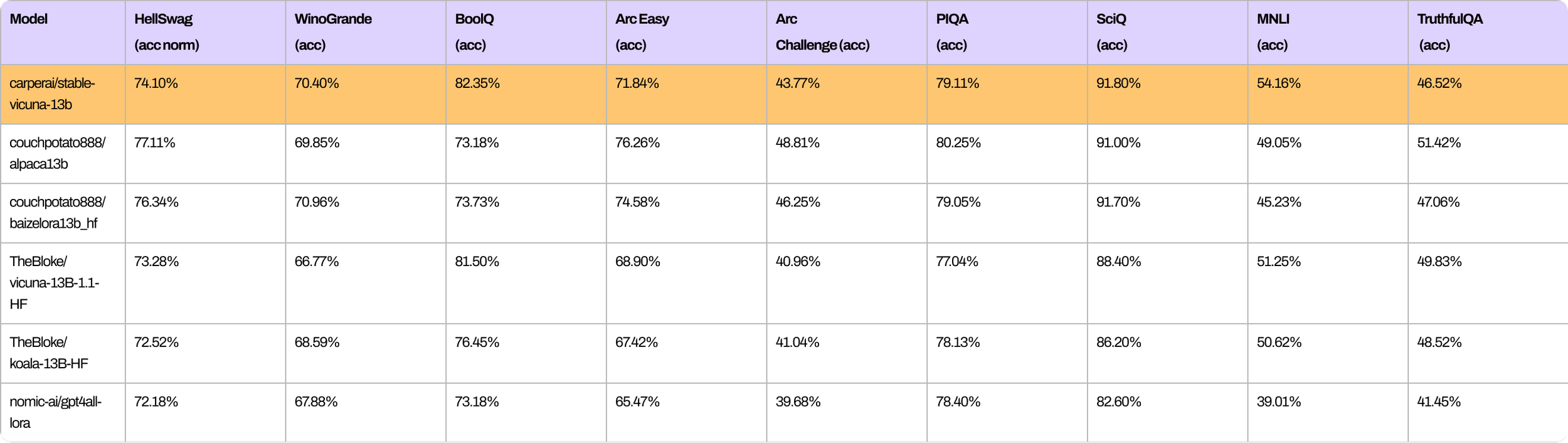
Del mismo modo, aquí hay una serie de puntos de referencia que muestran el rendimiento general de StableVicuna en comparación con otros chatbots de código abierto de tamaño similar.
Para lograr el sólido rendimiento de StableVicuna, utilizamos Vicuna como modelo base y seguimos el proceso típico de RLHF de tres etapas descrito por Steinnon et al. y Ouyang et al. Concretamente, entrenamos aún más el modelo base de Vicuña con ajuste fino supervisado (SFT) utilizando una combinación de tres conjuntos de datos:
OpenAssistant Conversations Dataset (OASST1), un corpus de conversación estilo asistente generado por humanos y anotado por humanos que comprende 161 443 mensajes distribuidos en 66 497 árboles de conversación, en 35 idiomas diferentes;
GPT4All Prompt Generations, un conjunto de datos de 437 605 mensajes y respuestas generados por GPT-3.5 Turbo;
Y Alpaca, un conjunto de datos de 52 000 instrucciones y demostraciones generadas por el motor text-davinci-003 de OpenAI.
Usamos trlx para entrenar un modelo de recompensa que primero se inicializa a partir de nuestro modelo SFT adicional en los siguientes conjuntos de datos de preferencias de RLHF:
El conjunto de datos de conversaciones de OpenAssistant (OASST1) contiene 7213 muestras de preferencias;
Anthropic HH-RLHF, un conjunto de datos de preferencias sobre la utilidad e inocuidad del asistente de IA que contiene 160 800 etiquetas humanas;
Y Stanford Human Preferences (SHP), un conjunto de datos de 348.718 preferencias humanas colectivas sobre las respuestas a preguntas/instrucciones en 18 áreas temáticas diferentes, desde cocina hasta filosofía.
Finalmente, usamos trlX para realizar el aprendizaje de refuerzo de optimización de política proximal (PPO) para realizar el entrenamiento RLHF del modelo SFT para llegar a StableVicuna.
Obtención de Vicuña Estable-13B
¡StableVicuna está, por supuesto, en HuggingFace Hub! El modelo se puede descargar como un peso delta contra el modelo LLaMA original. Para obtener StableVicuna-13B, puede descargar el delta de peso desde aquí. Sin embargo, tenga en cuenta que también debe tener acceso al modelo LLaMA original, lo que requiere que solicite los pesos LLaMA por separado mediante el enlace proporcionado en el repositorio de GitHub o aquí. Una vez que tenga tanto el peso delta como los pesos LLaMA, puede usar un script provisto en el repositorio de GitHub para combinarlos y obtener StableVicuna-13B.
Anuncio de nuestra próxima interfaz de chatbot
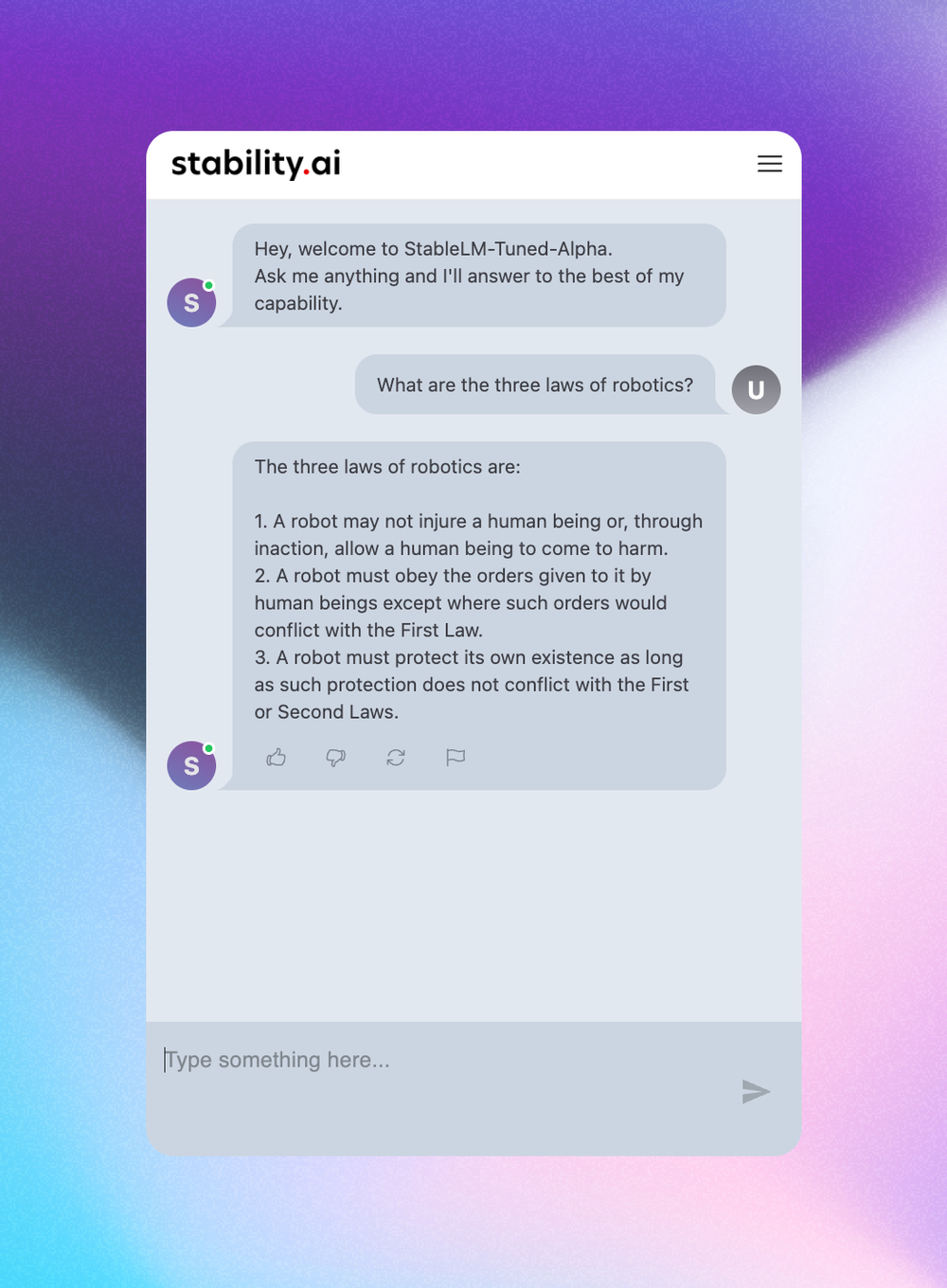
Junto con nuestro chatbot, nos complace presentar una vista previa de nuestra próxima interfaz de chat que se encuentra en las etapas finales de desarrollo. Las siguientes capturas de pantalla ofrecen una idea de lo que los usuarios pueden esperar.







![[tadoramo]](/images/smilies/adora.gif "Adorando")
![[beer]](/images/smilies/nuevos2/brindando.gif "brindis")

