Riwer escribió:J_Ark escribió:¿Mandando la gente al foro de Xbox One de EOL a informarse sobre rendimientos de ESRAM + DDR3 Vs. GDDR5? Entiendo.
También parece que por tus contribuciones al hilo te has informado (y bien informado) allí.
No, mejor convirtamos el hilo de huma, en el del debate del año sobre GDDR5 vs DDR3+ESRAM, no me puedo creer como no me habia dado cuenta de que esto era lo correcto y el destino de este hilo.
Faltaria mas, agradecido estoy de que me haya abierto los ojos...
Y tu quien eres? o mejor dicho, que haces aqui?
J_Ark escribió:Nadie. Sigue con el adoctrinamiento tecnológico. La latencia importa, los anchos de banda se suman, es imposible que Ps4 tenga hUMA por estar basado en jaguar y no en kaveri,...
litos001 escribió:Pero y realmente habrá mejoría por llevar esa tecnología?? Quiero decir, en la práctica real los usuarios lo notaremos?? yo lo dudo.
Se está comparando hUMA (heterogeneus Unified Memory Access) con Memoria Virtual.
Y no. Los tiros no van por ahí, porque efecticamente la memoria virtual es decir crear un espacio de memoria conjunto a partir de varios pools, pudiendo ser esos pools hasta de tipos de memoria diferentes, ya se lleva viendo en PC y consolas desde hace tiempo pero no es de lo que va hUMA.
hUMA es como AMD ha nombrado a su concepto de memoria unificada para HSA (Heterogeneous System Arquitecture), en el que CPU y GPU se complementan entre sí.
En este caso en el de hUMA, hablamos no de un espacio de memoria virtual, para empezar porque PS4 ya es arquitectura UMA (Unified Memory Access), porque solo tiene un único Pool de memoria y de un tipo. No tiene que virtualizar practicamente un carajo.
hUMA y de lo que se habla es que la CPU pueda acceder a las Cachés de la GPU y la GPU a la caché de la CPU, y de forma transparente (es decir rapida, sencilla y directa) y lo que es más importante que ese acceso es de forma coherente.
Si realmente PS4 monta una APU diseñada partiendo de hUMA hablamos de que los desarrolladores si programan un Engine ex professo para sacarle partido, pueden aprovechar y sacar bastante mas partido al hardware. Es decir esto no es algo que se ha puesto ahí como el que pone un parche. Es algo muy importante y que parten de una decisión fundamental de diseño. Y esto NO hace que la GPU tenga mas CUs, o por consiguiente mas ROPs, es decir mas potencia o que la CPU tenga mas núcleos y aumente su capacidad en coma flotante o en doble precisión. Pero sí que puede hacer que rindan mas, es decir que hagan mas cosas con lo mismo.
¿Hasta que punto aumenta el rendimiento?
Pues depende, francamente a día de hoy no hay nada por ahí que sea una APU HSA con hUMA, y que yo sepa no se ha desarrollado nada que le de uso en serio. A priori en unos cuantos aspectos sí que puede darles un empujón y bastante considerable, que combinado una capacidad mayor de calculo GPGPU de la GPU (que va reforzada con respecto a una gráfica similar de sobremesa, puede hacer que en aspectos como geometría, iluminación físicas, y IA, sonido, etc, etc, tengan un muy buen empujón.
Lo que no sé es hasta que punto.
¿Cuanto tardaremos en verlo y donde?
Tardaremos todavía bastante tiempo. Para empezar lo normal es que solo se vea en juegos exclusivos de estudios internos First y Second Party de Sony. Y OJO en juegos de 2ª hornada, o de 3ª.
Es decir si es cierto que PS4 monta una APU que cuenta con una arquitectura hUMA, para aprovecharlo tendrán que ser Engines hechos ex professo. Y el desarrollo de un engine nuevo tarda de 18 a 30 meses. Y las compañías que están desarrollando para PS4 incluido las First Party de Sony, es decir los estudios internos, para juegos como Killzone: Shadow Fall o Infamous son versiones actualizadas de sus Engines para PS3, porque basicamente al no tener el Hardware final no se iban a poner a desarrollar un engine 100% nuevo y menos si tenían que tener juegos para el lanzamiento.
Asi que olvidaos de ver que los juegos de lanzamiento first party puedan dar uso a algo como esto. Y mucho menos los Multiplataforma de lanzamiento.
Se verá en juegos Exclusivos pero tardará com pronto para finales de 2014 y yo apuntaría mas bien a 2015.
Si se llega a ver en Multiplataformas o no, dependerá de las herramientas que aporte Sony con el tiempo, y del éxito de la plataforma.
Si es o no hUMA y de serlo, saber el cuando se le dara uso pues es cuestion de tiempo y esperar
Natsu escribió:Pero lo que se supone que se consigue con HUMA no se consigue con la sram esa? pregunto, por que juraría haber leído hace tiempo las "bondades" de la esram de la juani y la descripción era casi calcada.
Natsu escribió:Pero lo que se supone que se consigue con HUMA no se consigue con la sram esa? pregunto, por que juraría haber leído hace tiempo las "bondades" de la esram de la juani y la descripción era casi calcada.
![[+risas]](/images/smilies/nuevos/risa_ani3.gif "más risas") Lo dicho, ni repajolera idea.
Lo dicho, ni repajolera idea. f5inet escribió:asi que, tanto XboxONE como PS4 son hUMA.
.
![[ayay]](/images/smilies/nuevos/sonrojado_ani1.gif "enrojecido") , por ello lo que decia Riwer y a mi tampoco me parecia muy correcto pues afirmar cosas sin tener ni las hojas blancas es dificil de digerir
, por ello lo que decia Riwer y a mi tampoco me parecia muy correcto pues afirmar cosas sin tener ni las hojas blancas es dificil de digerirAcaba de salir hace 5 minutos (esta vez nos hemos adelantado a gaf xd) éste documento en la web que filtró todas las especificaciones de Xbox One y PS4 a primeros de año.
Anuncian que van a sacar más información. Esta con la traducción de google y ligeramente revisado, después de comer lo vuelvo a mirar para que se entienda un poco mejor, aunque no es sencillo.
http://www.vgleaks.com/playstation-4-in ... echnology/
PlayStation 4 incluye tecnología HUMA
Ha habido mucha controversia sobre este asunto en los últimos días, pero vamos a tratar de aclarar que Playstation 4 soporta la tecnología Huma o por lo menos que implementa una primera revisión de la misma. Tenemos que recordar que AMD no ha lanzado productos con tecnología Huma todavía , por lo que es difícil comparar con algo en el mercado. Además, hay especificaciones están terminados todavía se resuelven, por lo tanto PS4 aplicación puede diferir un poco de las implementaciones con Huma finalizado.
Pero ante todo, ¿qué es Huma ? Huma es el acrónimo de Uniform Memory Access heterogénea . En el caso de Huma ambos procesadores ya no distinguen entre la CPU y la GPU áreas de memoria. Tal vez esta imagen podría explicar el concepto de una manera sencilla:
Si usted desea aprender más acerca de esta tecnología, este artículo se explica cómo funciona Huma.
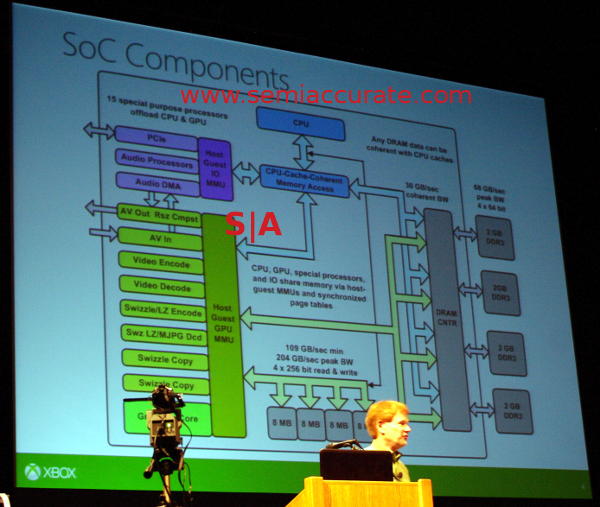
PS4 tiene mejoras en la arquitectura de memoria que ningún otro producto "menor" tiene como Marcos Cerny señaló en distintas entrevistas. Vamos a tratar de mostrar las nuevas piezas en PS4 componentes en las páginas siguientes.
Tenemos que poner nuestro diagrama sobre la arquitectura de memoria de PS4 para explicar cómo funciona.
Cartografía de la memoria en Liverpool
- Direcciones son de 40 bits. Este tamaño permite que las páginas de memoria asignadas tanto en CPU y GPU tengan la misma dirección virtual
- Páginas de la memoria son establecidas libremente por la aplicación
- Páginas de memoria no tienen que ser a la vez asignada en la CPU y la GPU
Si sólo la CPU va a utilizar, la GPU no tiene por qué lo han asignado
Si sólo el GPU va a utilizar, se accederá a través de Ajo
- Si la CPU y la GPU accederán a la página de memoria, la determinación debe hacerse si la GPU debe acceder a ella a través de cebolla o ajo
Si la GPU necesita gran ancho de banda, la página debe ser accesible a través de Ajo, la CPU tendrá que acceder a él memoria, no en caché
Si la CPU tiene acceso frecuente a la página, debe ser asignada como memoria caché de la CPU, la GPU tendrá que acceder a ella a través de cebolla.
Cinco Tipo de Buffers
- Buffers de memoria del sistema que utiliza la GPU etiquetados como uno de los cinco tipos de memoria
- Los tres primeros tipos tienen acceso a la CPU muy limitado, el acceso principal es por la GPU
- Sólo lectura (RO)
Un buffer "RO" es la memoria que se lee por CU de pero nunca escrito a ellos, por ejemplo, una textura o una mesa vértice
El acceso a memorias intermedias de ósmosis inversa nunca puede causar cachés L1 a pierden coherencia entre sí, ya que es escribir las operaciones que causan problemas de coherencia.
- Privada (PV)
Un buffer "PV" es la memoria privada leer y escribir mediante un solo ThreadGroup, por ejemplo, una memoria intermedia temporal.
El acceso a los búferes de PV nunca pueden causar cachés L1 a pierden coherencia, ya que es escribe en compartidos áreas de memoria que causan los problemas
- GPU coherente (GC)
Un buffer "GC" es la memoria leer y escribir mediante el CU de como resultado de las llamadas dibujar o despachos, por ejemplo, salidas de vertex shaders / que luego son leídos por los shaders de geometría. Topes de profundidad y destinos de representación no son de memoria GC, ya que no se escriben en la CU, pero por hardware dedicado en el DB y CBs.
Como escribe se permite buffers GC, el acceso a ellos puede causar cachés L1 de perder la coherencia con los demás
- Los dos últimos tipos son accesibles por la CPU y GPU
- El sistema coherente (SC)
Un buffer "SC" es la memoria leídos y escritos por tanto a la CPU y la GPU, por ejemplo, la CPU lee la estructura de la GPU, o estructuras utilizadas para la comunicación CPU-GPU
Buffers SC presentan los mayores problemas de coherencia. No sólo se puede cachés L1 pierden coherencia con otras, pero ambos L1 y L2 pueden perder la coherencia con la memoria del sistema y los cachés de CPU.
- Uncached (UC)
Un buffer "UC" es la memoria que se lee y se escribe en la CPU y GPU, al igual que la SC fue
Buffers UC no se almacenan en caché en el GPU L1 o L2, por lo que no presentan problemas de coherencia
UC accede a utilizar la nueva cebolla + bus, un bus de ancho de banda limitado similar al bus Cebolla
Accesos UC pueden tener importantes ineficiencias debido a repetidas lecturas de la misma línea o actualizaciones incrementales de las líneas
- Los tres primeros tipos (RO, PV, GC) pueden también tener acceso a la CPU, pero hay que tener cuidado. Por ejemplo, cuando se copia una textura a una nueva ubicación
La CPU puede escribir los datos de la textura de una manera no está en caché, a continuación, eliminar manualmente los caches GPU. La GPU puede, posteriormente, acceder a la textura como la memoria RO través de Ajo a alta velocidad
Dos peligros se evitan aquí. A medida que la CPU worte los datos de textura utilizando Uncached escribe, no quedan datos en la caché de la CPU y la GPU es de uso gratuito ajo en vez de cebolla. Como la CPU enrojeció las cachés GPU después de la configuración de la textura, no hay posibilidad de datos obsoletos en la GPU L1 y L2.
Seguimiento del tipo de accesos a memoria
- Accesos a memoria se hacen a través de V y T # # definiciones que contienen la dirección de base y otros parámetros de la memoria intermedia o la textura
- Tres bits se han añadido a V y T # # para especificar el tipo de memoria
- Y poco más se ha añadido a las etiquetas L1
Se establece si la línea se carga desde la memoria de GC o SC (en oposición a la memoria RO o PV)
Un nuevo tipo de L1 basada en paquetes invalidar se ha añadido que sólo invalida la líneas de GC y SC
Una estrategia simple es para código de aplicaciones para usar esta invalidación ante cualquier llamada empate o despacho que tiene acceso a GC o tampones SC
- Bit adicional se ha añadido a la L2 etiquetas
Indica si la línea se carga desde la memoria SC
Un nuevo L2 invalida apenas de las líneas SC se ha añadido
Un nuevo L2 reescritura de algo las líneas SC ha añadido. Estos dos están basadas en paquetes.
Una estrategia simple es para código de aplicaciones para utilizar la L2 invalida ante cualquier llamada empate o despacho que utiliza amortiguadores SC, y el uso de la L2 reescritura después de cualquier llamada empate o despacho que utiliza buffers SC
La combinación de estas características permite la adquisición eficiente y liberación de buffers de llamadas empate y despachos
Ejemplo simple:
- Vamos a tomar el caso en la mayor parte de la GPU está siendo utilizado para los gráficos (vertex shaders, shaders de pixel y así sucesivamente)
- Por otra parte, supongamos que tenemos un despacho cálculo asincrónico que utiliza una memoria tampón SC para:
Despacho entradas con son creados por la CPU y leído por el GPU
Despacho salidas, que se crean por la GPU y leídos por la CPU
- La GPU puede:
1) Adquirir el buffer SC mediante la realización de una L1 invalida (GC y SC) y L2 invalida (sólo las líneas SC). Esto elimina la posibilidad de datos obsoletos en las cachés. Cualquier dirección SC encontró irán adecuadamente offchip (en la memoria del sistema o caches de CPU) para recuperar los datos.
2) Ejecutar el sombreado cálculo
3) Suelte el buffer SC realizando una reescritura L2 (sólo líneas SC). Esto escribe todos los bytes sucios de nuevo a la memoria del sistema en la CPU pueda verlos
- El procesamiento de gráficos está mucho menos afectado por esta estrategia
Por R10XX, la L2 completo se inundó, por lo que los datos de uso de los shaders gráficos (por ejemplo, las texturas actuales) tendrían que ser recargada
El Liverpool, que los datos RO permanece en el lugar - como lo hace los datos de PV y GC
Esta información técnica puede ser un poco abrumador y confundir, por lo tanto, vamos a divulgar más información y ejemplos de uso de esta arquitectura en un nuevo artículo de esta semana .
):“El principal problema al que se enfrenta una GPU de un PC habitual, según Cerny, son las cachés internas de la GPU. Existe un bus que la GPU utiliza para acceder a la VRAM y luego tenemos otro bus secundario que va hasta la PCI Express y que la GPU utiliza para acceder a la memoria del sistema. Pero sea cual sea el bus utilizado, las cachés internas de la GPU se convierten en una gran barrera en la comunicación de la CPU y la GPU. Para intentar evitarlo se propusieron realizar algunas modificaciones clave en la arquitectura de la consola:
Han añadido un bus que permite acceder a la memoria del sistema desde la GPU pasando por encima de sus cachés L1 y L2 y con eso se consigue una comunicación directa entre la GPU y la CPU acelerando el proceso. Si el tamaño de los datos en ese proceso es pequeño se consigue una sincronización perfecta. Y por pequeña Mark Cerny se refiere a 20 GB por segundo, una medida grande a día de hoy pero muy habitual dentro de unos años.
El uso de la caché L2 de la GPU se ha intentado optimizar. Tanto la CPU como la propia GPU pueden escribir en la caché L2 de la GPU. Vamos, que la caché de la L2 de la GPU se puede utilizar de manera simultánea por el procesamiento gráfico como por las operaciones asíncronas de la CPU. Se las han apañado para añadir un bit volátil que marque líneas de la caché para saber diferenciarlas. Esa innovación permite que la CPU utilice la caché L2 de la GPU y ejecute las operaciones sin que tengan impacto en el rendimiento de las operaciones gráficas ejecutándose al mismo tiempo.”
marx666 escribió:Yo veo unanimidad general en distintos foros, en que lo que usa Xbox one no es Huma, si no el mismo sistema que ya usaba 360 pero potenciado.
Y según comentario del mismo Cerny acerca de como funciona la memoria en Ps4, parece bastante parecido a lo que es Huma realmente (o lo que yo he podido entender a nivel "se lo justo"
xaviejt escribió:A mi el Cerny este cada dia me parece mas payaso y sabelotodo,menudo ostion que acabara pegando.
Laguna_I escribió:xaviejt escribió:A mi el Cerny este cada dia me parece mas payaso y sabelotodo,menudo ostion que acabara pegando.
Un payaso? Lol? Si se lo está currando de lo lindo.
J_Ark escribió:Pues al final Ps4 si es hUMA compliant y Xbox One no (por limitaciones de acceso de la CPU a la ESRAM). So sad.


KidBeta escribió:Skeff escribió:KakesuSora escribió:What is hUMA though?
Basically:
Memory used by cpu and gpu without additional copying.
Its far more complicated than that, but that's essentially what it is, every time something is copied from one place to the other it slows the system down and hUMA prevents this from happening so GPGPU in particular is far more efficient.
This is not the whole story because the XBONE has a single address space that both the GPU and the CPU use. What the XBONE seems to be lacking is the decent way of flushing the cache of the GPU that the PS4 has, meaning that any coherent access between the CPU and GPU on the XBONE will be more expensive (assuming it has to flush its entire cache).
ElTorro escribió:On the R10xx, the complete L2 was flushed, so any data in use by the graphics shaders (e.g. the current textures) would need to be reloaded.
is, as far as I understand it correctly, something the PS4 can do but the XB1 can't. At least the other leaked documents on vgleaks state that the XB1's GPU caches have to be flushed completely.
ElTorro escribió:velociraptor escribió:So what does this mean for games?
More efficient use of GPGPU for calculating stuff. This here is an example of GPGPU-accelerated fur simulation (proprietary to NVIDIA, but it's valid as a general example):
(before/after)
Also, the interaction between CPU/GPU is more efficient, for instance, the exchange of display lists (rendering instructions).
anexanhume escribió:I think the takeaway from all of this is flexibility for the developers. They can choose whether or not the CPU and GPU accesses need to be coherent to one another and whether caches need to be flushed. They're not flushing a CPU cache when the GPU is doing a GPU only write, for example. Seems to be specifically architected to avoid bottlenecks and wasted resources.
ThePowerofX escribió:Digital Foundry: I seem to recall you might have talked about a toolchain where code could be compiled either for CPU or GPU. Is that right or have I got that completely wrong?
Mark Cerny: Such a toolchain does exist. It's AMD's HSA [Heterogeneous System Architecture]. That's very exciting but our current strategies are about exposing the low-level aspects of the GPU to a higher-level language. We think that's where the greatest benefit is in year one.
Darklor01 escribió:http://www.bit-tech.net/news/hardware/2013/04/30/amd-huma-heterogeneous-unified-memory-acces/"HUMA is essentially just a bit of branding that refers to the single memory address space the company's upcoming HSA APUs will be using. It harks back to the Unified Memory Access nomenclature of early multicore CPUs - where each CPU core started to share the same memory - adding in heterogeneous in reference to HSA.
HSA isn't just an AMD project, though, it is centred around the HSA Foundation "whose goal is to make it easyto program for parallel computing." The foundation includes such other high profile members as ARM, Qualcomm and Samsung.
The arrival of HSA is still some way off, with the first AMD chips set to use the architecture expected to arrive early next year. However, the PlayStation 4 is expected to feature an HSA type processor, so we'll see some indication of what we can look forward to when that console arrives in Q4 this year."
f5inet escribió:J_Ark escribió:Pues al final Ps4 si es hUMA compliant y Xbox One no (por limitaciones de acceso de la CPU a la ESRAM). So sad.
PD: mejor que me lo tome con humor... 'cache coherent'=hUMA. no hay mas.

f5inet escribió:resumen rapido de la HotChips:
Empezamos el dia pensando que XONE era entre un 40 y un 50% inferior a PS4. despues de la HotChips, el monton de cores que el SoC incorpora para tareas añadidas (la mas importante de ellas, el sonido, que se supone sera muy importante en la nextgen) hacen que las cosas esten ahora mismo muy parejas.
lo unico en lo que PS4 saca ventaja real en hardware a XONE es en ROPs de GPU (fillrate o tasa de rellenado), con 32ROPs en PS4 por 16ROPs en XONE.
sin embargo, y contrariamente a lo que se pudiera pensar, la XONE ahora es muy superior en ancho de banda de RAM. tiene un ancho de banda combinado de 270GB/s a RAM (202+68), por 176GB/s que ofrece PS4, memoria que recordemos, tiene mas latencia.
al final, y puesto que el fillrate o tasa de rellenado depende tanto del numero de ROPs como del ancho de banda de la RAM, podemos resumir en que estan parejas en este caso.
sin embargo, es posible que los Indies se vean mejor en PS4.

lherre escribió:Por favor que alguien diga que un chip de 25 gigaflops (SHAPE para el sonido) va a igualar un déficit de 500 gigaflops (usables para sonido si se quiere) me hace mucha gracia ...
![[triston]](/images/smilies/nuevos/triste_ani2.gif "tristón")
wabo escribió:lherre escribió:Por favor que alguien diga que un chip de 25 gigaflops (SHAPE para el sonido) va a igualar un déficit de 500 gigaflops (usables para sonido si se quiere) me hace mucha gracia ...
Pero no entiendes que al ser un chip para sonido esos gigaflops son májicos y rinden 20 veces más que los 500 gigaflops contrarios
![[decaio]](/images/smilies/nuevos2/decaido.gif "decaido")
J_Ark escribió:f5inet escribió:J_Ark escribió:Pues al final Ps4 si es hUMA compliant y Xbox One no (por limitaciones de acceso de la CPU a la ESRAM). So sad.
PD: mejor que me lo tome con humor... 'cache coherent'=hUMA. no hay mas.
Rite rite
El derrape de ayer bien, no?f5inet escribió:resumen rapido de la HotChips:
Empezamos el dia pensando que XONE era entre un 40 y un 50% inferior a PS4. despues de la HotChips, el monton de cores que el SoC incorpora para tareas añadidas (la mas importante de ellas, el sonido, que se supone sera muy importante en la nextgen) hacen que las cosas esten ahora mismo muy parejas.
lo unico en lo que PS4 saca ventaja real en hardware a XONE es en ROPs de GPU (fillrate o tasa de rellenado), con 32ROPs en PS4 por 16ROPs en XONE.
sin embargo, y contrariamente a lo que se pudiera pensar, la XONE ahora es muy superior en ancho de banda de RAM. tiene un ancho de banda combinado de 270GB/s a RAM (202+68), por 176GB/s que ofrece PS4, memoria que recordemos, tiene mas latencia.
al final, y puesto que el fillrate o tasa de rellenado depende tanto del numero de ROPs como del ancho de banda de la RAM, podemos resumir en que estan parejas en este caso.
sin embargo, es posible que los Indies se vean mejor en PS4.
![[plas]](/images/smilies/aplauso.gif "Aplausos") , otro punto a tu favor.
, otro punto a tu favor. J_Ark escribió:f5inet escribió:J_Ark escribió:Pues al final Ps4 si es hUMA compliant y Xbox One no (por limitaciones de acceso de la CPU a la ESRAM). So sad.
http://imgon.net/di-T1MH.gif
PD: mejor que me lo tome con humor... 'cache coherent'=hUMA. no hay mas.
Rite rite
El derrape de ayer bien, no?f5inet escribió:resumen rapido de la HotChips:
Empezamos el dia pensando que XONE era entre un 40 y un 50% inferior a PS4. despues de la HotChips, el monton de cores que el SoC incorpora para tareas añadidas (la mas importante de ellas, el sonido, que se supone sera muy importante en la nextgen) hacen que las cosas esten ahora mismo muy parejas.
lo unico en lo que PS4 saca ventaja real en hardware a XONE es en ROPs de GPU (fillrate o tasa de rellenado), con 32ROPs en PS4 por 16ROPs en XONE.
sin embargo, y contrariamente a lo que se pudiera pensar, la XONE ahora es muy superior en ancho de banda de RAM. tiene un ancho de banda combinado de 270GB/s a RAM (202+68), por 176GB/s que ofrece PS4, memoria que recordemos, tiene mas latencia.
al final, y puesto que el fillrate o tasa de rellenado depende tanto del numero de ROPs como del ancho de banda de la RAM, podemos resumir en que estan parejas en este caso.
sin embargo, es posible que los Indies se vean mejor en PS4.
![[mad]](/images/smilies/nuevos/miedo.gif "loco")
shinobi66 escribió:[...]
y se supone que f5inet es uno de los entendidos de eol
![[reojillo]](/images/smilies/nuevos2/ooooops.gif "reojillo")
f5inet escribió:shinobi66 escribió:[...]
y se supone que f5inet es uno de los entendidos de eol
me conoces muy bien para solo llevar 6 mensajes en esta comunidad... no se como tomarmelo...
Pero lo que dije fue porque por tu actitud daba la impresión que entendías de lo que hablabas sin embargo tus palabras te contradecían. 
 pero bueno, lo pongo por aquí por si alguien le interesa:
pero bueno, lo pongo por aquí por si alguien le interesa:JohnDoe escribió:En reddit un "desarrollador" de Microsoft afirma que la One si implementa huma, aunque creo que dicen algo de que puede ser un tema de las directx y que sea por software... la verdad que no me entero muy bien de todo lo que comentan
http://www.reddit.com/r/xboxone/comment ... ar/cbswrn3
totalmente creíble sip. lherre escribió:Un desarrollador que no sabe ni lo que es huma (dice que no le suena hasta ahora)
lherre escribió:JohnDoe escribió:En reddit un "desarrollador" de Microsoft afirma que la One si implementa huma, aunque creo que dicen algo de que puede ser un tema de las directx y que sea por software... la verdad que no me entero muy bien de todo lo que comentan
http://www.reddit.com/r/xboxone/comment ... ar/cbswrn3
Un desarrollador que no sabe ni lo que es huma (dice que no le suena hasta ahora)
PoderGorrino escribió:lherre escribió:JohnDoe escribió:En reddit un "desarrollador" de Microsoft afirma que la One si implementa huma, aunque creo que dicen algo de que puede ser un tema de las directx y que sea por software... la verdad que no me entero muy bien de todo lo que comentan
http://www.reddit.com/r/xboxone/comment ... ar/cbswrn3
Un desarrollador que no sabe ni lo que es huma (dice que no le suena hasta ahora)
Hombre, un clásico, reddit tiene credibilidad 99% cuando me interesa y 0% cuando no... xD
PoderGorrino escribió:Hombre, un clásico, reddit tiene credibilidad 99% cuando me interesa y 0% cuando no... xD
![[buenazo]](/images/smilies/nuevos/risa_tonta.gif "buenazo")
JohnDoe escribió:[...]
Existe algo seguro al 100% sobre este tema? jejeje
Pagina 5: 1.5 implementation components
An HSA implementation is a system that passes the HSA Compliance Test Suite. It consists of:
• A heterogeneous hardware platform that integrates both LCUs (NdeT: CPU) and TCUs (NdeT: GPU), which operate coherently in shared memory.
• A software compilation stack consisting of a compiler, linker and loader.
• A user-space runtime system, which also includes debugging and profiling capabilities.
• Kernel-space system components.
pagina 148: implementation considerations
The IOMMU’s translation cache must support the following operations:
• Lookup — when the IOMMU processes an access by a particular device to a specified device virtual address, it applies protection checks and translation transformations using information obtained using DeviceID and device virtual address.
• Invalidate device — discard any translation cache contents that depend on a specific device table entry.
• Invalidate virtual address (within domain) — discard any cached translations for a virtual address within the specified domain.
f5inet escribió:JohnDoe escribió:[...]
Existe algo seguro al 100% sobre este tema? jejeje
si, lo existe, y es la documentacion que ha distribuido AMD sobre la arquitectura HSA/hUMA:
para que una arquitectura sea denomina hUMA y por tanto, compatible HSA, debe tener un pool unificado de memoria principal, accesos a traves de mas de varios buses simultaneamente, y debe implementar un mecanisno de coherencia de cache entre las caches de los buses.
el como decidan implementarlo cada uno de los fabricantes, y las optimizaciones que quieran hacerle, ya queda bajo su discrecion, que mientras implementen un sistema que mantenga la coherencia de cache, todo bien...
PAPER de la arquitectura HSA de AMD
http://support.amd.com/us/Processor_TechDocs/48882.pdfpagina 148: implementation considerations
The IOMMU’s translation cache must support the following operations:
• Lookup — when the IOMMU processes an access by a particular device to a specified device virtual address, it applies protection checks and translation transformations using information obtained using DeviceID and device virtual address.
• Invalidate device — discard any translation cache contents that depend on a specific device table entry.
• Invalidate virtual address (within domain) — discard any cached translations for a virtual address within the specified domain.
 , con lo de si hay algo seguro me refería al tema de las consolas, se asegura al 100% de que PS4 es huma, pero después hay informaciones contradictorias. Con la XBOX ONE se asegura 100% que NO tiene huma, pero después hay informaciones contradictorias. Vamos, que yo personalmente saco en claro que seguro 100% no hay nada.
, con lo de si hay algo seguro me refería al tema de las consolas, se asegura al 100% de que PS4 es huma, pero después hay informaciones contradictorias. Con la XBOX ONE se asegura 100% que NO tiene huma, pero después hay informaciones contradictorias. Vamos, que yo personalmente saco en claro que seguro 100% no hay nada. . El tema de lo que se comentaba en reddit lo puse por que me pareció interesante, solo eso, yo no busco aseverar ni adoptrinar sobre si una es peor o mejor. Son solo consolas, para jugar
. El tema de lo que se comentaba en reddit lo puse por que me pareció interesante, solo eso, yo no busco aseverar ni adoptrinar sobre si una es peor o mejor. Son solo consolas, para jugar JohnDoe escribió:[...]
Buena info
Aviso que yo ni fu, ni fa... el tema me interesa pero no es algo sobre lo que yo vaya a debatir ni hablar mal de una ni de otra, ni decir si este miente o este tiene la verdad absoluta, simplemente me gusta aprender cosas y tener conocimientos
JohnDoe escribió:lherre escribió:Un desarrollador que no sabe ni lo que es huma (dice que no le suena hasta ahora)
No voy a ser yo quien ponga la mano en el fuego por lo que puedan o no puedan hacer / tener la ps4 / xbox one, jejeje, ni lo que alguien diga.
Pero si no estoy equivocado huma es terminología de AMD, y si no entiendo mal el desarrollador cuando lee sobre huma tira de la documentación por que le parece haber leído sobre ello, no con la palabra huma, si con lo que implica.
(CUDA?)f5inet escribió:si, lo existe, y es la documentacion que ha distribuido AMD sobre la arquitectura HSA/hUMA:
para que una arquitectura sea denomina hUMA y por tanto, compatible HSA, debe tener un pool unificado de memoria principal, accesos a traves de mas de varios buses simultaneamente, y debe implementar un mecanisno de coherencia de cache entre las caches de los buses.
el como decidan implementarlo cada uno de los fabricantes, y las optimizaciones que quieran hacerle, ya queda bajo su discrecion, que mientras implementen un sistema que mantenga la coherencia de cache, todo bien...
PAPER de la arquitectura HSA de AMD:
http://developer.amd.com/wordpress/medi ... /hsa10.pdf
...
vaya, justo lo que yo decia... COHERENCIA DE CACHE=HSA COMPLIANT
As we promised in our previous article, we present new information about the enhancements in the memory system on PlayStation 4.
Bypass Bits
- If many of these sorts of compute shaders are being run simultaneously, there is “cross talk” in that one compute dispatch may forcé an invalidate or a premature flush of another dispatch’s SC memory
- As a result of this (and other factors), it may be optimal to bypass either the L1, or the L2, or both
Bypassing all caches for the accesses to the shared CPU-GPU memory (effectively making the data UC rather than SC) will remove the need for the invalidates and writebacks of L1 and L2
At the same time, there will be more – perhaps much more – traffic to and from system memory
- It is possible to change the V# and T# definitions on a dispatch by dispatch basis when exploring these issues and tuning the application
- However, in order to allow for a more stable and debugable programming approach
Two override bits have been added to the draw call and dispatch controls
The L1 bypass bit specifies that operations on GC and SC memory bypass the L1 and go directly to L2
The L2 bypass bit specifies that operations on SC memory bypass the L2, using the new “Onion+” bus
This allows the application programmer to use same shader code and V#/T# definitions, and then run the shaders with several different cache flush strategies. No recompilation or reconfiguration is required
Four Memory Buffer Usage Examples
1) Simple Rendering
- Vertex shader and pixel shader only; the pixel shader does not direct memory accesses
- Vertex buffers (RO)
- Textures (RO)
- Color and depth buffers are written using dedicated hardware mechanisms, not memory buffers
2) Raycast
- In order to compute visibility (“can the enemy see the player”) or sound effect volume (“is there a direct path from audio source to player”), sets of 64 rays are compared against large triangle databases
- Triangle databases (RO)
- Input rays (SC)
- Output collisions (SC)
- The raycast probably doesn’t use much SC data and could potentially entirely bypass L2
3) Procedural Geometry (e.g. water surface)
- The CPU maintains a high level state of the water (ripples, splashes coming for interactions with game objects). The GPU generates the detailed water mesh, with is used only for rendering
- Input: water state as maintained by CPU (SC)
- Output: detailed water surface (GC)
4) Chained compute shaders
- Compute shaders write semaphores for the CP to read, enabling other compute dispatches (and perhaps draw calls) to run. They also add packets to compute pipe queues (perhaps packets that kick off more compute dispatches)
- Various buffers (RO, PV, GC, SC)
- Semaphores (UC)
- Compute pipe queue (UC)
- NOTE that CP does not have access to the GPU L2, so semaphores and queue contents must either be assigned the SC memory type (visible to the CP only after a L2 writeback) or the UC memory type (which bypases the L2)
- Using UC can allow for greater flexibility, e.g. a compute dispatch can have several stages that send and receive semaphores. Using SC requires the dispatch to terminate before the semaphore is visible externally
Strategies for Scalar Loads
- In addition to the “gather read” and “scatter write” loads into VGPRs (Vector GPRs), the R10xx core also supports scalar reads and writes into SGPRs (Scalar GPRs)
Typically, scalar reads are used to load T#, V#, and S# structures, as well as any other data that applies to the wavefront as a whole (as opposed to the vector reads that load data on a thread-by-thread basis)
- These read operations use the L2, but instead of the L1 they use a different cache called the “K-cache”. There is one 16 KB K-cache for each three CU’s
The K-cache must be invalidated when there is the possibility that it may contain “stale” data, e.g. a later draw call or dispatch uses the same location in the T# (etc) ring buffer as an earlier call
K-cache invalidation takes 1 cycle but dumps all data, resulting in a high cost
The most straightforward way of reducing the invalidation count is to use larger ring buffers for the scalar input data to the draw calls and dispatches
Performance
- Performance of the L2 cache operations is much better on Liverpool than on R10xx
- The L2 invalidate typically takes 300-350 cycles
All in-flight memory transactions must settle before the invalidate can be completed
A small overhead (about 75 cycles) is required to locate and invalidate the lines
This results in the direct cost listed above. There is also an indirect cost, in that invalidated SC data must potentially be reloaded
- The cost of an L2 writeback depends on the amount of data that must be written back to system memory
The Onion bus can support 10GB/sec, which means 12.5 bytes/cycle (0.2 lines/cycle)
If we attribute 160 GB/sec of the Garlic bus to the GPU, the bus can support 200 bytes/cycle (3.125 lines/cycle)
- If there is only a little SC dirty data present in the L2, the writeback is fairly fast
4K bytes worth of dirty Onion SC lines will take perhaps 500 cycles (Onion bottleneck PLUS small overhead to locate lines PLUS latency to system memory)
20K bytes worth of dirty Garlic SC lines will take about the same time
- Worst case L2 writeback cost is basically the Onion or Garlic cost of writing 512 KB (about 40,000 cycles and 3,000 cycles respectively)
Additional Optimizations
- There are additional further optimizations in the L1 and L2 caches
- The L2 cache has dirty state tracking
If the L2 has performed no reads from SC memory since the last invalidate, it will ignore any requests to invalidate
If the L2 has performed no writes to SC memory since the last writeback, it will ignore any requests to perform a writeback
This will help performance in the situation where multiple pipes are requesting invalidates and writebacks, e.g. several compute pipes are separately dispatching compute shaders that use SC memory
- The L1 cache can be invalidated “once per CU”
A dispatch may send multiple wavefronts to a single CU
Using this option, the invalidate of GC/SC occurs only on the first wavefront of the dispatch
Polyteres escribió:Buenas gente. Esto no es así. En el mismo paper q has puesto de AMD sobre HSA lo pone bien claro. Por una parte se está confundiendo lo q es HSA y lo q es hUMA. hUMA es una característica (organización de memoria), q entre muchas otras, debe poseer un sistema para ser HSA.
Dicho lo cual: Ps4 si es hUMA, XboxOne no lo es. Y no lo es por una cosa muy sencilla...la eSRAM.
Para q un sistema tenga una organización hUMA tiene q tener entre otras cosas un espacio de direcciones unificado. Cumple esto la arquitectura de XboxOne?. NO, la eSRAM es una memoria que no puede ser tocada de ninguna manera por la CPU, por lo q al no poder direccionar la CPU dicha memoria, no cumple con tener un espacio unificado de direcciones. No hay mas, la primera característica no la cumple por lo q no es hUMA compilant.
Que tiene un bus de acceso coherente a memoria DDR3?. Vale, y?. Al no tener un espacio de direcciones único...ya no es hUMA.
Un saludo.
![[tadoramo]](/images/smilies/adora.gif "Adorando")
Polyteres escribió:f5inet escribió:si, lo existe, y es la documentacion que ha distribuido AMD sobre la arquitectura HSA/hUMA:
para que una arquitectura sea denomina hUMA y por tanto, compatible HSA, debe tener un pool unificado de memoria principal, accesos a traves de mas de varios buses simultaneamente, y debe implementar un mecanisno de coherencia de cache entre las caches de los buses.
el como decidan implementarlo cada uno de los fabricantes, y las optimizaciones que quieran hacerle, ya queda bajo su discrecion, que mientras implementen un sistema que mantenga la coherencia de cache, todo bien...
PAPER de la arquitectura HSA de AMD:
http://developer.amd.com/wordpress/medi ... /hsa10.pdf
...
vaya, justo lo que yo decia... COHERENCIA DE CACHE=HSA COMPLIANT
Buenas gente. Esto no es así. En el mismo paper q has puesto de AMD sobre HSA lo pone bien claro. Por una parte se está confundiendo lo q es HSA y lo q es hUMA. hUMA es una característica (organización de memoria), q entre muchas otras, debe poseer un sistema para ser HSA.
Dicho lo cual: Ps4 si es hUMA, XboxOne no lo es. Y no lo es por una cosa muy sencilla...la eSRAM.
Para q un sistema tenga una organización hUMA tiene q tener entre otras cosas un espacio de direcciones unificado. Cumple esto la arquitectura de XboxOne?. NO, la eSRAM es una memoria que no puede ser tocada de ninguna manera por la CPU, por lo q al no poder direccionar la CPU dicha memoria, no cumple con tener un espacio unificado de direcciones. No hay mas, la primera característica no la cumple por lo q no es hUMA compilant.
Que tiene un bus de acceso coherente a memoria DDR3?. Vale, y?. Al no tener un espacio de direcciones único...ya no es hUMA.
Un saludo.
Polyteres escribió:Dicho lo cual: Ps4 si es hUMA, XboxOne no lo es. Y no lo es por una cosa muy sencilla...la eSRAM.
Para q un sistema tenga una organización hUMA tiene q tener entre otras cosas un espacio de direcciones unificado. Cumple esto la arquitectura de XboxOne?. NO, la eSRAM es una memoria que no puede ser tocada de ninguna manera por la CPU, por lo q al no poder direccionar la CPU dicha memoria, no cumple con tener un espacio unificado de direcciones. No hay mas, la primera característica no la cumple por lo q no es hUMA compilant.
Que tiene un bus de acceso coherente a memoria DDR3?. Vale, y?. Al no tener un espacio de direcciones único...ya no es hUMA.
Un saludo.
f5inet escribió:la verdad es que me estoy cansando de estos debate esteriles, porque tengo la impresion que hay determinadas personas que por unas razones u otras (economicas, laborales, pasionales, etc) tienen una idea inamobible, y por mas que se aporten datasheets, ponencias o incluso PDFs oficiales de arquitectura, no van a dar su brazo a torcer.
f5inet escribió:sin embargo, y contrariamente a lo que se pudiera pensar, la XONE ahora es muy superior en ancho de banda de RAM. tiene un ancho de banda combinado de 270GB/s a RAM (202+68), por 176GB/s que ofrece PS4, memoria que recordemos, tiene mas latencia.
![[carcajad]](/images/smilies/nuevos/risa_ani2.gif "carcajada") .
.f5inet escribió:Yo digo que la XboxONE es 'compatible hUMA' porque la memoria principal es la DDR3 y al eSRAM solo actua de cache para la GPU (una especie de cache L3) y el canal de control de la CPU a la eSRAM permite la coherencia de cache.
f5inet escribió:Que cada cual crea lo que quiera. he tenido PS3 y X360 en esta generacion, y espero tener PS4 y XONE en la siguiente, y espero que ambas sean hUMA para que ambas puedan implementar megatexturas por hardware, y no con el terrible poping que tenia Rage.
![[qmparto]](/images/smilies/net_quemeparto.gif "Que me parto!")







![[sonrisa]](/images/smilies/nuevos/risa_ani1.gif "sonrisa")
