dunkam82 escribió:
1º Ni siquiera se ha teniendo en cuenta el número de CUs, cosa que es una cagada. Yo no soy ingeniero ni nada parecido pero si se están haciendo unas operaciones en las que estás multiplicando por la frecuencias de reloj, tendrás que multiplicar también por el número de CU´s que ejecutan esas frecuencias, si no lo haces es asumir que ambas tienen el mismo número de CUs y no es así cuando una tiene 36 y la otra tiene 52.
Claro que así salen en esas cuentas la PS5 como ganadora, ahora mete el número de CUs en la ecuación a ver qué pasa.
2º Se está dando por hecho en esas "cuentas" que la frecuencia de la GPU va a ir siempre al máximo, porque claro es lo que interesa para que te salga PS5 vencedora, pero te recuerdo que la PS5 tiene frecuencias variables y además tiene que ir distribuyendo la potencia entre la CPU y la GPU por lo que ni de coña va a ir siempre al máximo.
Entre otras cosas porque si han hecho lo de las frecuencias variables es por problemas de temperatura, si no fuese así, Sony hubiera puesto a trabajar a tope de forma fija la GPU y la CPU al máximo, como ha hecho Microsoft con Series X, y no hubiera hecho esa chapuza.
3º Se está dando por hecho que la subida de las frecuencias de reloj tienen un incremento lineal de la potencia cuando tampoco es así, hay por ahí varios análisis (uno de ellos creo que de Digital Foundry) en el que prueban con una 5700XT que es RDNA 1 (lo más cercano que tenemos al 2) y se va viendo como llegado a cierto punto el aumento de la velocidad no repercute en su equivalente en potencia/rendimiento.
4º Se está dando por hecho para el tema del Ray Tracing que la mayor frecuencia de reloj compensn la diferencia del número de CUs, pero lo cierto es que para el cálculo de Ray Tracing la ganancia con mayor número de CUs es mucho mayor que por frecuencias más altas .... y Series X tiene un 44% más de CU´s que PS5.
En fin creo que después de estos 4 puntos queda claro que todas esas cuentas y cálculos, sea quien sea que los haya hecho no sirven para NADA.
silenius escribió:dunkam82 escribió:
1º Ni siquiera se ha teniendo en cuenta el número de CUs, cosa que es una cagada. Yo no soy ingeniero ni nada parecido pero si se están haciendo unas operaciones en las que estás multiplicando por la frecuencias de reloj, tendrás que multiplicar también por el número de CU´s que ejecutan esas frecuencias, si no lo haces es asumir que ambas tienen el mismo número de CUs y no es así cuando una tiene 36 y la otra tiene 52.
Claro que así salen en esas cuentas la PS5 como ganadora, ahora mete el número de CUs en la ecuación a ver qué pasa.
2º Se está dando por hecho en esas "cuentas" que la frecuencia de la GPU va a ir siempre al máximo, porque claro es lo que interesa para que te salga PS5 vencedora, pero te recuerdo que la PS5 tiene frecuencias variables y además tiene que ir distribuyendo la potencia entre la CPU y la GPU por lo que ni de coña va a ir siempre al máximo.
Entre otras cosas porque si han hecho lo de las frecuencias variables es por problemas de temperatura, si no fuese así, Sony hubiera puesto a trabajar a tope de forma fija la GPU y la CPU al máximo, como ha hecho Microsoft con Series X, y no hubiera hecho esa chapuza.
3º Se está dando por hecho que la subida de las frecuencias de reloj tienen un incremento lineal de la potencia cuando tampoco es así, hay por ahí varios análisis (uno de ellos creo que de Digital Foundry) en el que prueban con una 5700XT que es RDNA 1 (lo más cercano que tenemos al 2) y se va viendo como llegado a cierto punto el aumento de la velocidad no repercute en su equivalente en potencia/rendimiento.
4º Se está dando por hecho para el tema del Ray Tracing que la mayor frecuencia de reloj compensn la diferencia del número de CUs, pero lo cierto es que para el cálculo de Ray Tracing la ganancia con mayor número de CUs es mucho mayor que por frecuencias más altas .... y Series X tiene un 44% más de CU´s que PS5.
En fin creo que después de estos 4 puntos queda claro que todas esas cuentas y cálculos, sea quien sea que los haya hecho no sirven para NADA.
Para esos calculos no se necesitan el numero de CU para nada
![[beer]](/images/smilies/nuevos2/brindando.gif "brindis")
dunkam82 escribió:Como he dicho no soy ingeniero, pero si estamos calculando algo con unas frecuencias de reloj que mueven unas unidades de computación (CU´s) explícame por qué no hace falta meter el número de CU´s en esas operaciones, argumenta tu respuesta para que entienda el por qué, que parece que lo tienes muy claro y uno siempre está dispuesto a aprender cosas nuevas.
Según mi lógica de por qué si hay que tener en cuenta el número de CU´s en otro ejemplo de algo que no tenga que ver con gráficos:
Imaginemos 2 coches eléctricos, uno de ellos tiene un motor eléctrico (CU´s) en 2 ruedas que tienen 100 CV (frecuencias de reloj) de potencia cada motor y luego está el otro que tiene un motor eléctrico en cada rueda, es decir en las 4 ruedas, pero tiene 75CV de potencia en cada motor.
Según esas cuentas sin tener en cuenta los CU´s, el coche con más potencia sería el primero porque claro comparamos 100CV vs 75CV, pero en la realidad cuando se tiene en cuenta el número de motores (CU´s) el coche con más potencia es el 2º que tiene 75CV x 4 = 300CV de potencia vs los 200CV que tiene el primero.
Por eso te digo que según mi lógica si hay que meter los CU´s en la ecuación si se están haciendo cálculos con las frecuencias de reloj, porque no es lo mismo 36 "relojes" funcionando a 200 que 52 relojes funcionando a 180.
Quedo a la espera de tu explicación
PD: Independientemente de que pueda estar errado en el primer punto (a la espera de vuestra explicación) aún están los otros 3 puntos que le quitan toda validez a esos cálculos
silenius escribió:dunkam82 escribió:Como he dicho no soy ingeniero, pero si estamos calculando algo con unas frecuencias de reloj que mueven unas unidades de computación (CU´s) explícame por qué no hace falta meter el número de CU´s en esas operaciones, argumenta tu respuesta para que entienda el por qué, que parece que lo tienes muy claro y uno siempre está dispuesto a aprender cosas nuevas.
Según mi lógica de por qué si hay que tener en cuenta el número de CU´s en otro ejemplo de algo que no tenga que ver con gráficos:
Imaginemos 2 coches eléctricos, uno de ellos tiene un motor eléctrico (CU´s) en 2 ruedas que tienen 100 CV (frecuencias de reloj) de potencia cada motor y luego está el otro que tiene un motor eléctrico en cada rueda, es decir en las 4 ruedas, pero tiene 75CV de potencia en cada motor.
Según esas cuentas sin tener en cuenta los CU´s, el coche con más potencia sería el primero porque claro comparamos 100CV vs 75CV, pero en la realidad cuando se tiene en cuenta el número de motores (CU´s) el coche con más potencia es el 2º que tiene 75CV x 4 = 300CV de potencia vs los 200CV que tiene el primero.
Por eso te digo que según mi lógica si hay que meter los CU´s en la ecuación si se están haciendo cálculos con las frecuencias de reloj, porque no es lo mismo 36 "relojes" funcionando a 200 que 52 relojes funcionando a 180.
Quedo a la espera de tu explicación
PD: Independientemente de que pueda estar errado en el primer punto (a la espera de vuestra explicación) aún están los otros 3 puntos que le quitan toda validez a esos cálculos
El primer calculo son los triangulos rasterizados. Esto lo procesa el rasterizador. Cada rasterizador puede procesar un triangulo por ciclo. Hay 1 rasterizador en cada shader array (hay 4 en total en el chip). Por lo que tienes 4 traingulos por ciclo y se multiplica por la frecuencia
El segundo calculo es el cull rate. Esto lo procesa las primitive units. Cada primitive unit puede procesar dos operaciones por ciclo. Hay una primitive unit por shader array (hay 4 en total en el chip). Por lo que tienes 8 operaciones por ciclo y se multiplica por la frecuencia.
El tercero es el pixel fillrate. Esto lo procesa los Render backend. Cada render backend tiene 4 rops. Por lo que tienes 16 rops por shader array (hay 4 en total en el chip). Por lo que tienes 64 rops en total que se multiplican por la frecuencia
El cuarto es el texture fillrate. Esto lo procesa las texture mapping unit o TMU. Cada CU tiene 4. Cada shader array tiene 5 Dual compute o 10 CU por lo que tienes 20 TMU por shader array (hay 4 en total en el chip). Este caso como no es un chip con 4 shader array completos se multiplica en numero de CU x 4 y se multi`lica por la frecuencia.
El quinto es el calculo de ray tracing. Esto prefiero esperar a ver como lo ha resuleto AMD ya que aun no sabemos como funcionará exactamente en rdna2.
El sexto es el calculo de TF. Cada Cu tiene 64 ALU o stream processors. Si se tienen 36 Cu se tienen 2304 ALU (que son las de ps5) El numero sale de: frecuencia x ALU x 2. Es el unico calculo en el que si intervienen las CU
Pd.- Todos estos calculos son valores maximos y siempre se basan en el pico maximo de frecuencia, 2'23Ghz en el caso de ps5 y 1'825Ghz en XsX
![[poraki]](/images/smilies/nuevos/dedos.gif "por aquí!") Muy bien explicado,
Muy bien explicado,dunkam82 escribió:Muchísimas gracias por la explicación
La cuestión que me queda tras leerlo es ¿de dónde sale que siendo SOC diferentes y totalmente personalizados, a parte de ser más grande y con un 44% más de CU´s el de Series X, que ambas tienen el mismo número de rasterirzadores, de primitive units y de render backend?
Porque pregunto desde la ignorancia pero si se tiene en cuenta la velocidad a la que funcionan esos CU´s para hacer los cálculos, entonces esos elementos van en función a los CU´s y por tanto a mayor número de CU´s mayor número de rasterizadores, primitive units y render backend ¿no?
![[carcajad]](/images/smilies/nuevos/risa_ani2.gif "carcajada") ) estan basadas en la misma, RDNA2
) estan basadas en la misma, RDNA2 Nuhar escribió:Se comenta por los foros que el precio de Warner seria de 4b$ que en un mundo racional son 4.000 millones.
La compra incluye unos cuantos estudios (sobre 15)pero no las licencias de warner films, solo las ips propias de cada estudio.
Nuhar escribió:Se comenta por los foros que el precio de Warner seria de 4b$ que en un mundo racional son 4.000 millones.
La compra incluye unos cuantos estudios (sobre 15)pero no las licencias de warner films, solo las ips propias de cada estudio.
xhakarr escribió:Nuhar escribió:Se comenta por los foros que el precio de Warner seria de 4b$ que en un mundo racional son 4.000 millones.
La compra incluye unos cuantos estudios (sobre 15)pero no las licencias de warner films, solo las ips propias de cada estudio.
Que ips propias tienen?

dunkam82 escribió:
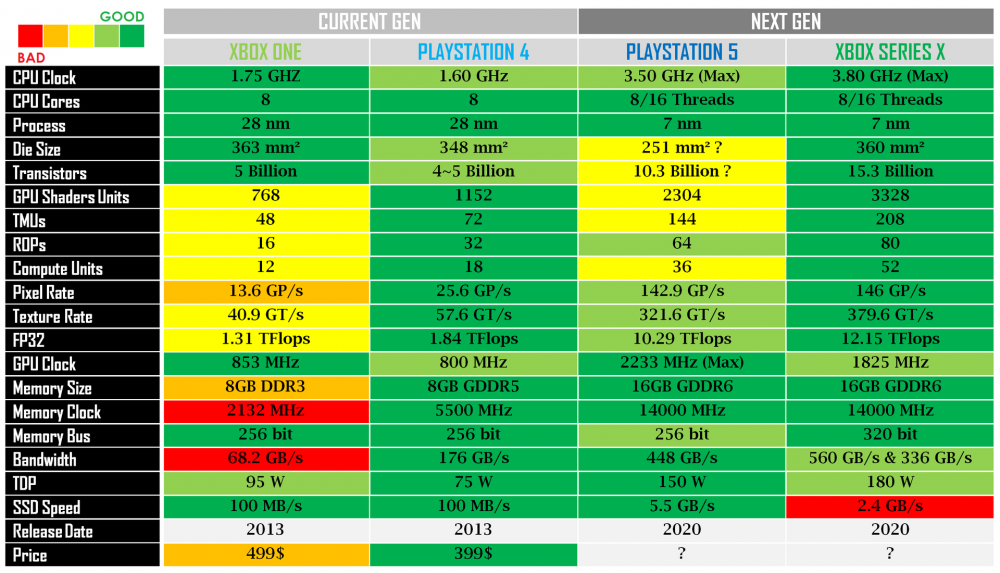
manmartin escribió:@silenius esos cálculos parten de que las dos tienen 64 rops,no? Se rumorea que series ese tiene 80 rops
xhakarr escribió:Parece que alguien de ign ha confirmado fable

Nowcry escribió:Después de mucho estudiar puedo demostrar teóricamente que la XBox Serx NO TIENE CUELLO DE BOTELLA en L1 a diferencia de lo que pasaba en RDNA1.
Ojo que es denso pero después de mucho estudiar (me aburro con el confinamiento) creo que lo he conseguido.
Voy a empezar con los cálculos de una GPU de RDNA1 para tener una referencia y porque podemos comprobar los resultados y saber si estamos bien.
Resultados según fabricante : L0 bandwith 9,76 TB/s L1 Bandwith 3.90 TB/s L2 Bandwith 1.95 TB/s
560 GB/s / 320 bits * 8 = 40 canales / 8 canales por controlador de memoria de 64 bits = 5 controladores de memoria o arrays de CU.
RDNA1 GPU Boots Clock 1905 MHz CU = 40 ancho de banda = 448 GB/s interface memoria 256 bits.
Reloj de Memoria 1750 Mhz.
Lo primero es sacar el reloj base a las que funcionan las cache, (1905 MHz / 1750 MHz) * 448 = 487.68 GB/s Esta es la velocidad de los controladores de memoria.
Ancho de banda cache L2 = 487.68 * 4 controladores de memoria = 1950.72 GB/s = lo del fabricante
Ancho de banda cache L1 = el doble que L2 = 3900 GB/s = lo del fabricante
Ancho de banda cache L0 = Reloj base * numero de cache L0 = 487.68*20 = 9750 GB/s = lo del fabricante
Ahora hago lo mismo en Xbox:
Calculamos el reloj base de las cache (1860/1750) * 560 = 595.2 GB/s
Ancho de banda cache L2 = 595.2 GB/s * 5 controladores de memoria = 2976 GB/s
Ancho de banda cache L1 = el doble que la L2 = 5952 GB/s
Ancho de banda cache L0 = 595.2 * 26 cache L0 (1 por cada 2 CU) = 15475.2 GB/s
Ahora hago lo mismo en PS5:
Calculamos el reloj base de las cache (2260/1750) * 448 = 578.56 GB/s
Ancho de banda cache L2 = 578.56 GB/s * 4 controladores de memoria = 2314.24 GB/s
Ancho de banda cache L1 = el doble que la L2 = 4628.48 GB/s
Ancho de banda cache L0 = 578.56 * 20 cache L0 = 11571.2 GB/s
(esta vez no es 1 por cada 2 CU han metido 4 arrays de 9 CU osea hay 1 CU sola en un DCU)
Ahora hago lo mismo en 2080Ti:
Calculamos el Reloj base de las cache: (1350/1750) * 616 = 475.2 GB/s
Ancho de banda cache L2 = 475.2 * 6 controladores de memoria = 2851.2 GB/s
Ancho de banda cache L1 = 475.2 * 68 SM = 32313.6 GB/s
Y ahora es cuando viene la comprobación de fuego:
El consumo teórico de una CU/SM esta basado en que tiene 64 unidades de calculo en FP32.
Desarrollo formula:
5700XT
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1860*10^6 ) *1 instruction rate / 8 Bits to Byte = 476.16 GB/s. para Xbox
Xbox SerX
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1905*10^6 ) *1 instruction rate / 8 Bits to Byte = 487.68 GB/s. para GPU RDNA1
PS5:
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 578.56 GB/s. para GPU RDNA1
(64 (FP32 ) * cada stream procesor FP32 cogerá un paquete de 32 bits de L0 * Clock 1350*10^6 ) *1 instruction rate / 8 Bits to Byte + (64 (INT32 ) * cada stream procesor INT32 cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 345.6 GB/s + 345.6 GB/s = 691.2 GB/s. Después de mucho leer en el libro Whitebook de nvidia dice que han conseguido usar una compresión en la memoria del 50% y que es esencial para mantener la arquitectura centrada. 691.2/1.5 = 460.5 SOlo nos queda creernoslo. Pero por lo visto la descompresion llega hasta las Shaders Unit y Texture Units.
Whitepaper Nvidia pagina 27.
Saquemos numeros por CU:
Lcache GPU RDNA1
L2 cache 1950/40 = 48.75 GB/s
L1 cache 3900/40 = 97.5 GB/s
L0 cache 9750/40 = 244 GB/s
TOTAL 390.25 GB/s <<<<487.68 GB/s
Cuello de botella famoso Cache bandwich/
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 80%
XBOX SerX
2976/52 = 57.23 GB/s
5952 / 52 = 114.4615
15475.2 / 52 = 297.6
57.23+114.46+297.6 = 470 GB/s == 476.16 (Las diferencias de poco serán decimales o algo)
COMO ANILLO AL DEDO han hecho el OC exacto
Cache Bandwidth/FLOP CU 470 / 476.68 = 98.6% sera del 100% por los decimales.
Hago los números para PS5
2314.24/36 = 64.28 GB/s
4628.48 / 36 = 128.57
11571.2 / 36 = 321.42
57.23+114.46+297.6 = 514.26 GB/s <<< 578.65 GB/s Son las CU con mejor ancho de banda pero no podrán ejecutar ser alimentadas solo desde cache en el caso de que todas las operaciones que se hagan sean de 32 bits.
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 88.98% ---> 90 % por los decimales.
2080Ti
2851.2/68 = 41.93 GB/s
32313.6 / 68 =475.2 GB/s
TOTAL = 517.13 GB/s >>> 460.5 GB/s. Sin compresion <<<<691.2.
No estoy muy seguro de mis cuentas en Nvidia . Ademas de que me faltan los tensor y RT por meterlos pero no se ni por donde empezar. Por otro lado por lo visto Nvidia tiene una Cache L1.5 y tiene cache L0 pero hay muy poca información sobre ella.
Con esto quiero decir lo siguiere:
La Xbox SerX no tiene cuello de botella en L1 que ha sido corregido al poner 5 controladores de memoria y tener un reloj mas bajo que la 5700 XT. La arquitectura esta centrada en el rendimiento teórico. A su vez han diseñado la consola robusta con 12,15 tflops de potencia FP32 y los entrega sin margenes. Lo que hará sobrar ancho de banda en la mayor parte de las ocasiones, muy interesante si finalmente hay un modo windows y permite hacerle OC, de forma que se pudiera exprimir ese extra. Este ancho de banda podría ser útil en Raytracing pero quedo a la espera de ver la arquitectura real de RDNA2. Es un producto muy solido.
En PS5 las CU son las mejor alimentadas de todas las maquinas excepto de la 2080Ti pero la arquitectura esta centrada al rendimiento económico. Esto no es malo porque hay un estudio en el Whitepaper de Nvidia en el que estudia estadisticamente cuantas operaciones de FP32 hay en el mismo ciclo.
El estudio dice que alrededor del 30% de los cálculos son escalares. Cada juego es diferente pero el margen estadístico sitúa la que varia entre [10%-50%]. Ademas de cálculos que no ocupan los 32 bits y también habrá algunos cálculos de FP16. Lo que diseñar las APU con un 10% de margen por debajo esta tocando el mínimo de la variaran y es una buena forma de diseñar y ahorrar dinero. Para mi es el OC exacto para desarrollar toda la potencia y que de cada euro gastado se saque el máximo provecho. La parte negativa es que no hay margen para RT y quedo a la espera de ver la arquitectura REAL haber descubierto esto me incita a pensar que va ha haber cambios en cuanto al ancho de banda de las cache del paso de RDNA1 a 2 o quizá algún tipo de compresión de datos.
Como digo todo puede ser papel mojado si en RDNA2 han mejorado el ancho de banda de alguna cache, lo cual debería ser lo lógico, la cache L0 debería mejorarse para dar entrada al RTX en cualquiera de las 2 maquinas, o la utilización de compresión al estilo de Nvidia para dar cabida a los datos que chuparan RTX. Podría darse la inclusión de un L0 por CU en vez de cada dos CU para evitar el cuello de botella que generan al ir haciendo OC.
En mi entendimiento esto sitúa que los 12,15 Tflops de la Xbox podrán exprimirse y que los 10,21 Tflops también podrán exprimirse. La diferencia radica en que la Xbox puede tener 12,15 Tflops en coma flotante 32 al mismo tiempo. Y la PS5 tendrá 10,21 Tflops pero solo podrá genera unos 9.189 Tflops en coma flotante 32 y el resto se quedaría a la espera. O podría generar 8 Tflops en coma flotante 32 y 2,21 Tflops en coma flotante 16. Como digo todo esto es si los datos que tenemos las consolas se configuraran como RDNA 1 5700XT. No debéis tomar esto como algo malo ni un engaño, todos los juegos desde el mejor al peor tienen un mínimo un 10% de cálculos que no son en FP32 y un máximo de 50%. Una CU aunque tenga ancho de banda si esta haciendo una FLOP a 16 o con escalares no puede realizar una en FP32. Tener eso en cuenta para mi es ahorro y es el OC exacto para exprimir al máximo.
Recomiendo estar atentos a ver si hay cambios en las cache y como se alimenta RTX. Pero en principio para hacerse una idea esta bien.
En cuanto al SSD, para mi generara un cambio enorme en los videojuegos tanto a diseño como gráficamente.
Debo decir que es un SSD menor que otro en principio no debería lastrar la una a la otra y se podría optar por reducir las texturas mas alejadas en la Xbox de forma que se ajustara el ancho de banda y la diferencia seria mínima. De la misma forma que 2 Tflops. Una calcularía mas polígonos y en la otra se podrían reducir en las estructuras mas alejadas que son los menos efectivos pero se llevan los mismos cálculos.
El SSD lo que nos va a permitir es poder poner en el tiro de la camara mucha mas memoria debido a que ya no hay que cargar lo que va a pasar a 30 segundos vista. Si tardas 2-4 segundos en renovar la GDDR completa, con 2 seg PS5 o 4 segundos Xbox. Esto hará que sea la primera vez que en un tiro de cámara podamos ver entre (9-12 GB de VRAM del tirón) incluido en PC que el unico juego que aprovecha el SSD realmente es StarCitizen.
Calculo que como mas o menos vemos los modelos poligonales de los objetos con las consolas actuales 4,5-6 Tflops parecen perfectos, lo que si que ha flojeado esta generación es en texturas que se cargaba los modelos y en la cantidad de objetos distintos (VARIABILIDAD).
Debido a este nuevo ancho de banda, las texturas podrán mejorar considerablemente y a su vez la variabilidad podrá por fin entrar en escena. Es posible que sea el cambio mas emocionante desde PS2. Ya que en la variabilidad tanto de objetos como de texturas esta el realismo.
Espero haberos mejorado la tarde, y haberos pegado mi entusiasmo por la nueva GEN.
Se que algunas de mis teorías van dando bandazos de un lado al otro, pero según aprendo mas cosas van cambiando porque voy descubriendo errores en mis interpretaciones, también algunas basadas en errores o "simplificaciones" de las explicaciones de AMD en su documentación que después leyendo mas detenidamente o según avanzo en el libro voy aprendiendo cosas que pensaba que no se podían hacer abriendo camino.
Quien sabe quizá dentro de 3 días descubra algo y cambie de nuevo toda mi teoría.
Como es un tocho no espero que nadie se lo lea pero lo dejo aquí a modo de apuntes. Y creo que voy a dejar un tiempo de estudiar hardware que llevo ya una semana enfrascado en aprender como funciona y ahora que creo que he resuelto el puzzle quedo a la espera de que den mas detalles.
Un saludo.
silenius escribió:manmartin escribió:@silenius esos cálculos parten de que las dos tienen 64 rops,no? Se rumorea que series ese tiene 80 rops
Si, calculos con la presuncion de que son 64 rops. Lo que de que se rumorea, ya dije que creo que hicieron las cuentas de la lechera y por eso salen 80. Si no se ha modificado el estandar de 16 rops por shader array no llevará mas de 64. Pero como todavia no hemos visto ningun diagrama de las gpu de ninguna ni Ms ni Sony sueltan prenda pues es todo especular. No sabemos hasta que punto han personalizado el diseño o cuanto han modificado.
ENLACEThe Scarlett graphics processor is a large chip with a die area of 360 mm² and 14,750 million transistors. It features 3328 shading units, 208 texture mapping units, and 80 ROPs. AMD includes 10 GB GDDR6 memory, which are connected using a 320-bit memory interface. The GPU is operating at a frequency of 1825 MHz, memory is running at 1750 MHz.
![[fumando]](/images/smilies/nuevos/fumando.gif "fumando")
pixius escribió:Nowcry escribió:Después de mucho estudiar puedo demostrar teóricamente que la XBox Serx NO TIENE CUELLO DE BOTELLA en L1 a diferencia de lo que pasaba en RDNA1.
Ojo que es denso pero después de mucho estudiar (me aburro con el confinamiento) creo que lo he conseguido.
Voy a empezar con los cálculos de una GPU de RDNA1 para tener una referencia y porque podemos comprobar los resultados y saber si estamos bien.
Resultados según fabricante : L0 bandwith 9,76 TB/s L1 Bandwith 3.90 TB/s L2 Bandwith 1.95 TB/s
560 GB/s / 320 bits * 8 = 40 canales / 8 canales por controlador de memoria de 64 bits = 5 controladores de memoria o arrays de CU.
RDNA1 GPU Boots Clock 1905 MHz CU = 40 ancho de banda = 448 GB/s interface memoria 256 bits.
Reloj de Memoria 1750 Mhz.
Lo primero es sacar el reloj base a las que funcionan las cache, (1905 MHz / 1750 MHz) * 448 = 487.68 GB/s Esta es la velocidad de los controladores de memoria.
Ancho de banda cache L2 = 487.68 * 4 controladores de memoria = 1950.72 GB/s = lo del fabricante
Ancho de banda cache L1 = el doble que L2 = 3900 GB/s = lo del fabricante
Ancho de banda cache L0 = Reloj base * numero de cache L0 = 487.68*20 = 9750 GB/s = lo del fabricante
Ahora hago lo mismo en Xbox:
Calculamos el reloj base de las cache (1860/1750) * 560 = 595.2 GB/s
Ancho de banda cache L2 = 595.2 GB/s * 5 controladores de memoria = 2976 GB/s
Ancho de banda cache L1 = el doble que la L2 = 5952 GB/s
Ancho de banda cache L0 = 595.2 * 26 cache L0 (1 por cada 2 CU) = 15475.2 GB/s
Ahora hago lo mismo en PS5:
Calculamos el reloj base de las cache (2260/1750) * 448 = 578.56 GB/s
Ancho de banda cache L2 = 578.56 GB/s * 4 controladores de memoria = 2314.24 GB/s
Ancho de banda cache L1 = el doble que la L2 = 4628.48 GB/s
Ancho de banda cache L0 = 578.56 * 20 cache L0 = 11571.2 GB/s
(esta vez no es 1 por cada 2 CU han metido 4 arrays de 9 CU osea hay 1 CU sola en un DCU)
Ahora hago lo mismo en 2080Ti:
Calculamos el Reloj base de las cache: (1350/1750) * 616 = 475.2 GB/s
Ancho de banda cache L2 = 475.2 * 6 controladores de memoria = 2851.2 GB/s
Ancho de banda cache L1 = 475.2 * 68 SM = 32313.6 GB/s
Y ahora es cuando viene la comprobación de fuego:
El consumo teórico de una CU/SM esta basado en que tiene 64 unidades de calculo en FP32.
Desarrollo formula:
5700XT
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1860*10^6 ) *1 instruction rate / 8 Bits to Byte = 476.16 GB/s. para Xbox
Xbox SerX
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1905*10^6 ) *1 instruction rate / 8 Bits to Byte = 487.68 GB/s. para GPU RDNA1
PS5:
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 578.56 GB/s. para GPU RDNA1
(64 (FP32 ) * cada stream procesor FP32 cogerá un paquete de 32 bits de L0 * Clock 1350*10^6 ) *1 instruction rate / 8 Bits to Byte + (64 (INT32 ) * cada stream procesor INT32 cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 345.6 GB/s + 345.6 GB/s = 691.2 GB/s. Después de mucho leer en el libro Whitebook de nvidia dice que han conseguido usar una compresión en la memoria del 50% y que es esencial para mantener la arquitectura centrada. 691.2/1.5 = 460.5 SOlo nos queda creernoslo. Pero por lo visto la descompresion llega hasta las Shaders Unit y Texture Units.
Whitepaper Nvidia pagina 27.
Saquemos numeros por CU:
Lcache GPU RDNA1
L2 cache 1950/40 = 48.75 GB/s
L1 cache 3900/40 = 97.5 GB/s
L0 cache 9750/40 = 244 GB/s
TOTAL 390.25 GB/s <<<<487.68 GB/s
Cuello de botella famoso Cache bandwich/
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 80%
XBOX SerX
2976/52 = 57.23 GB/s
5952 / 52 = 114.4615
15475.2 / 52 = 297.6
57.23+114.46+297.6 = 470 GB/s == 476.16 (Las diferencias de poco serán decimales o algo)
COMO ANILLO AL DEDO han hecho el OC exacto
Cache Bandwidth/FLOP CU 470 / 476.68 = 98.6% sera del 100% por los decimales.
Hago los números para PS5
2314.24/36 = 64.28 GB/s
4628.48 / 36 = 128.57
11571.2 / 36 = 321.42
57.23+114.46+297.6 = 514.26 GB/s <<< 578.65 GB/s Son las CU con mejor ancho de banda pero no podrán ejecutar ser alimentadas solo desde cache en el caso de que todas las operaciones que se hagan sean de 32 bits.
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 88.98% ---> 90 % por los decimales.
2080Ti
2851.2/68 = 41.93 GB/s
32313.6 / 68 =475.2 GB/s
TOTAL = 517.13 GB/s >>> 460.5 GB/s. Sin compresion <<<<691.2.
No estoy muy seguro de mis cuentas en Nvidia . Ademas de que me faltan los tensor y RT por meterlos pero no se ni por donde empezar. Por otro lado por lo visto Nvidia tiene una Cache L1.5 y tiene cache L0 pero hay muy poca información sobre ella.
Con esto quiero decir lo siguiere:
La Xbox SerX no tiene cuello de botella en L1 que ha sido corregido al poner 5 controladores de memoria y tener un reloj mas bajo que la 5700 XT. La arquitectura esta centrada en el rendimiento teórico. A su vez han diseñado la consola robusta con 12,15 tflops de potencia FP32 y los entrega sin margenes. Lo que hará sobrar ancho de banda en la mayor parte de las ocasiones, muy interesante si finalmente hay un modo windows y permite hacerle OC, de forma que se pudiera exprimir ese extra. Este ancho de banda podría ser útil en Raytracing pero quedo a la espera de ver la arquitectura real de RDNA2. Es un producto muy solido.
En PS5 las CU son las mejor alimentadas de todas las maquinas excepto de la 2080Ti pero la arquitectura esta centrada al rendimiento económico. Esto no es malo porque hay un estudio en el Whitepaper de Nvidia en el que estudia estadisticamente cuantas operaciones de FP32 hay en el mismo ciclo.
El estudio dice que alrededor del 30% de los cálculos son escalares. Cada juego es diferente pero el margen estadístico sitúa la que varia entre [10%-50%]. Ademas de cálculos que no ocupan los 32 bits y también habrá algunos cálculos de FP16. Lo que diseñar las APU con un 10% de margen por debajo esta tocando el mínimo de la variaran y es una buena forma de diseñar y ahorrar dinero. Para mi es el OC exacto para desarrollar toda la potencia y que de cada euro gastado se saque el máximo provecho. La parte negativa es que no hay margen para RT y quedo a la espera de ver la arquitectura REAL haber descubierto esto me incita a pensar que va ha haber cambios en cuanto al ancho de banda de las cache del paso de RDNA1 a 2 o quizá algún tipo de compresión de datos.
Como digo todo puede ser papel mojado si en RDNA2 han mejorado el ancho de banda de alguna cache, lo cual debería ser lo lógico, la cache L0 debería mejorarse para dar entrada al RTX en cualquiera de las 2 maquinas, o la utilización de compresión al estilo de Nvidia para dar cabida a los datos que chuparan RTX. Podría darse la inclusión de un L0 por CU en vez de cada dos CU para evitar el cuello de botella que generan al ir haciendo OC.
En mi entendimiento esto sitúa que los 12,15 Tflops de la Xbox podrán exprimirse y que los 10,21 Tflops también podrán exprimirse. La diferencia radica en que la Xbox puede tener 12,15 Tflops en coma flotante 32 al mismo tiempo. Y la PS5 tendrá 10,21 Tflops pero solo podrá genera unos 9.189 Tflops en coma flotante 32 y el resto se quedaría a la espera. O podría generar 8 Tflops en coma flotante 32 y 2,21 Tflops en coma flotante 16. Como digo todo esto es si los datos que tenemos las consolas se configuraran como RDNA 1 5700XT. No debéis tomar esto como algo malo ni un engaño, todos los juegos desde el mejor al peor tienen un mínimo un 10% de cálculos que no son en FP32 y un máximo de 50%. Una CU aunque tenga ancho de banda si esta haciendo una FLOP a 16 o con escalares no puede realizar una en FP32. Tener eso en cuenta para mi es ahorro y es el OC exacto para exprimir al máximo.
Recomiendo estar atentos a ver si hay cambios en las cache y como se alimenta RTX. Pero en principio para hacerse una idea esta bien.
En cuanto al SSD, para mi generara un cambio enorme en los videojuegos tanto a diseño como gráficamente.
Debo decir que es un SSD menor que otro en principio no debería lastrar la una a la otra y se podría optar por reducir las texturas mas alejadas en la Xbox de forma que se ajustara el ancho de banda y la diferencia seria mínima. De la misma forma que 2 Tflops. Una calcularía mas polígonos y en la otra se podrían reducir en las estructuras mas alejadas que son los menos efectivos pero se llevan los mismos cálculos.
El SSD lo que nos va a permitir es poder poner en el tiro de la camara mucha mas memoria debido a que ya no hay que cargar lo que va a pasar a 30 segundos vista. Si tardas 2-4 segundos en renovar la GDDR completa, con 2 seg PS5 o 4 segundos Xbox. Esto hará que sea la primera vez que en un tiro de cámara podamos ver entre (9-12 GB de VRAM del tirón) incluido en PC que el unico juego que aprovecha el SSD realmente es StarCitizen.
Calculo que como mas o menos vemos los modelos poligonales de los objetos con las consolas actuales 4,5-6 Tflops parecen perfectos, lo que si que ha flojeado esta generación es en texturas que se cargaba los modelos y en la cantidad de objetos distintos (VARIABILIDAD).
Debido a este nuevo ancho de banda, las texturas podrán mejorar considerablemente y a su vez la variabilidad podrá por fin entrar en escena. Es posible que sea el cambio mas emocionante desde PS2. Ya que en la variabilidad tanto de objetos como de texturas esta el realismo.
Espero haberos mejorado la tarde, y haberos pegado mi entusiasmo por la nueva GEN.
Se que algunas de mis teorías van dando bandazos de un lado al otro, pero según aprendo mas cosas van cambiando porque voy descubriendo errores en mis interpretaciones, también algunas basadas en errores o "simplificaciones" de las explicaciones de AMD en su documentación que después leyendo mas detenidamente o según avanzo en el libro voy aprendiendo cosas que pensaba que no se podían hacer abriendo camino.
Quien sabe quizá dentro de 3 días descubra algo y cambie de nuevo toda mi teoría.
Como es un tocho no espero que nadie se lo lea pero lo dejo aquí a modo de apuntes. Y creo que voy a dejar un tiempo de estudiar hardware que llevo ya una semana enfrascado en aprender como funciona y ahora que creo que he resuelto el puzzle quedo a la espera de que den mas detalles.
Un saludo.
volver a leer esto , solo en la ram la xsx le pasa por encima , con las cus tambien , refrigeracion RT dedicado , no hay debate , la cosa es que ps5 se a visto abocada a hacer overlocking a la gpu para no perder terreno y ya esta
Tmac_1 escribió:Vamos, que dirán precios en agosto en el reveal de la Series S.
Cómo Sony siga la costumbre de esperar a que Microsoft de precio nos plantamos en septiembre.
El hasta ahora fiable Jeff Grubb dice que lo de Iniciative se lo guardan para más adelante.
dunkam82 escribió:silenius escribió:manmartin escribió:@silenius esos cálculos parten de que las dos tienen 64 rops,no? Se rumorea que series ese tiene 80 rops
Si, calculos con la presuncion de que son 64 rops. Lo que de que se rumorea, ya dije que creo que hicieron las cuentas de la lechera y por eso salen 80. Si no se ha modificado el estandar de 16 rops por shader array no llevará mas de 64. Pero como todavia no hemos visto ningun diagrama de las gpu de ninguna ni Ms ni Sony sueltan prenda pues es todo especular. No sabemos hasta que punto han personalizado el diseño o cuanto han modificado.
Mira aquí no especulan aquí lo dan como dato que Series X tiene 80 ROPS lo cual tiene sentido con el Die Size más grande, están todas las specs completas o al menos bastantes del SOC.ENLACEThe Scarlett graphics processor is a large chip with a die area of 360 mm² and 14,750 million transistors. It features 3328 shading units, 208 texture mapping units, and 80 ROPs. AMD includes 10 GB GDDR6 memory, which are connected using a 320-bit memory interface. The GPU is operating at a frequency of 1825 MHz, memory is running at 1750 MHz.
Sabiendo que tiene 80ROPS ¿cómo quedarían las cuentas esas que se hacían antes?

pixius escribió:Nowcry escribió:Después de mucho estudiar puedo demostrar teóricamente que la XBox Serx NO TIENE CUELLO DE BOTELLA en L1 a diferencia de lo que pasaba en RDNA1.
Ojo que es denso pero después de mucho estudiar (me aburro con el confinamiento) creo que lo he conseguido.
Voy a empezar con los cálculos de una GPU de RDNA1 para tener una referencia y porque podemos comprobar los resultados y saber si estamos bien.
Resultados según fabricante : L0 bandwith 9,76 TB/s L1 Bandwith 3.90 TB/s L2 Bandwith 1.95 TB/s
560 GB/s / 320 bits * 8 = 40 canales / 8 canales por controlador de memoria de 64 bits = 5 controladores de memoria o arrays de CU.
RDNA1 GPU Boots Clock 1905 MHz CU = 40 ancho de banda = 448 GB/s interface memoria 256 bits.
Reloj de Memoria 1750 Mhz.
Lo primero es sacar el reloj base a las que funcionan las cache, (1905 MHz / 1750 MHz) * 448 = 487.68 GB/s Esta es la velocidad de los controladores de memoria.
Ancho de banda cache L2 = 487.68 * 4 controladores de memoria = 1950.72 GB/s = lo del fabricante
Ancho de banda cache L1 = el doble que L2 = 3900 GB/s = lo del fabricante
Ancho de banda cache L0 = Reloj base * numero de cache L0 = 487.68*20 = 9750 GB/s = lo del fabricante
Ahora hago lo mismo en Xbox:
Calculamos el reloj base de las cache (1860/1750) * 560 = 595.2 GB/s
Ancho de banda cache L2 = 595.2 GB/s * 5 controladores de memoria = 2976 GB/s
Ancho de banda cache L1 = el doble que la L2 = 5952 GB/s
Ancho de banda cache L0 = 595.2 * 26 cache L0 (1 por cada 2 CU) = 15475.2 GB/s
Ahora hago lo mismo en PS5:
Calculamos el reloj base de las cache (2260/1750) * 448 = 578.56 GB/s
Ancho de banda cache L2 = 578.56 GB/s * 4 controladores de memoria = 2314.24 GB/s
Ancho de banda cache L1 = el doble que la L2 = 4628.48 GB/s
Ancho de banda cache L0 = 578.56 * 20 cache L0 = 11571.2 GB/s
(esta vez no es 1 por cada 2 CU han metido 4 arrays de 9 CU osea hay 1 CU sola en un DCU)
Ahora hago lo mismo en 2080Ti:
Calculamos el Reloj base de las cache: (1350/1750) * 616 = 475.2 GB/s
Ancho de banda cache L2 = 475.2 * 6 controladores de memoria = 2851.2 GB/s
Ancho de banda cache L1 = 475.2 * 68 SM = 32313.6 GB/s
Y ahora es cuando viene la comprobación de fuego:
El consumo teórico de una CU/SM esta basado en que tiene 64 unidades de calculo en FP32.
Desarrollo formula:
5700XT
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1860*10^6 ) *1 instruction rate / 8 Bits to Byte = 476.16 GB/s. para Xbox
Xbox SerX
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1905*10^6 ) *1 instruction rate / 8 Bits to Byte = 487.68 GB/s. para GPU RDNA1
PS5:
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 578.56 GB/s. para GPU RDNA1
(64 (FP32 ) * cada stream procesor FP32 cogerá un paquete de 32 bits de L0 * Clock 1350*10^6 ) *1 instruction rate / 8 Bits to Byte + (64 (INT32 ) * cada stream procesor INT32 cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 345.6 GB/s + 345.6 GB/s = 691.2 GB/s. Después de mucho leer en el libro Whitebook de nvidia dice que han conseguido usar una compresión en la memoria del 50% y que es esencial para mantener la arquitectura centrada. 691.2/1.5 = 460.5 SOlo nos queda creernoslo. Pero por lo visto la descompresion llega hasta las Shaders Unit y Texture Units.
Whitepaper Nvidia pagina 27.
Saquemos numeros por CU:
Lcache GPU RDNA1
L2 cache 1950/40 = 48.75 GB/s
L1 cache 3900/40 = 97.5 GB/s
L0 cache 9750/40 = 244 GB/s
TOTAL 390.25 GB/s <<<<487.68 GB/s
Cuello de botella famoso Cache bandwich/
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 80%
XBOX SerX
2976/52 = 57.23 GB/s
5952 / 52 = 114.4615
15475.2 / 52 = 297.6
57.23+114.46+297.6 = 470 GB/s == 476.16 (Las diferencias de poco serán decimales o algo)
COMO ANILLO AL DEDO han hecho el OC exacto
Cache Bandwidth/FLOP CU 470 / 476.68 = 98.6% sera del 100% por los decimales.
Hago los números para PS5
2314.24/36 = 64.28 GB/s
4628.48 / 36 = 128.57
11571.2 / 36 = 321.42
57.23+114.46+297.6 = 514.26 GB/s <<< 578.65 GB/s Son las CU con mejor ancho de banda pero no podrán ejecutar ser alimentadas solo desde cache en el caso de que todas las operaciones que se hagan sean de 32 bits.
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 88.98% ---> 90 % por los decimales.
2080Ti
2851.2/68 = 41.93 GB/s
32313.6 / 68 =475.2 GB/s
TOTAL = 517.13 GB/s >>> 460.5 GB/s. Sin compresion <<<<691.2.
No estoy muy seguro de mis cuentas en Nvidia . Ademas de que me faltan los tensor y RT por meterlos pero no se ni por donde empezar. Por otro lado por lo visto Nvidia tiene una Cache L1.5 y tiene cache L0 pero hay muy poca información sobre ella.
Con esto quiero decir lo siguiere:
La Xbox SerX no tiene cuello de botella en L1 que ha sido corregido al poner 5 controladores de memoria y tener un reloj mas bajo que la 5700 XT. La arquitectura esta centrada en el rendimiento teórico. A su vez han diseñado la consola robusta con 12,15 tflops de potencia FP32 y los entrega sin margenes. Lo que hará sobrar ancho de banda en la mayor parte de las ocasiones, muy interesante si finalmente hay un modo windows y permite hacerle OC, de forma que se pudiera exprimir ese extra. Este ancho de banda podría ser útil en Raytracing pero quedo a la espera de ver la arquitectura real de RDNA2. Es un producto muy solido.
En PS5 las CU son las mejor alimentadas de todas las maquinas excepto de la 2080Ti pero la arquitectura esta centrada al rendimiento económico. Esto no es malo porque hay un estudio en el Whitepaper de Nvidia en el que estudia estadisticamente cuantas operaciones de FP32 hay en el mismo ciclo.
El estudio dice que alrededor del 30% de los cálculos son escalares. Cada juego es diferente pero el margen estadístico sitúa la que varia entre [10%-50%]. Ademas de cálculos que no ocupan los 32 bits y también habrá algunos cálculos de FP16. Lo que diseñar las APU con un 10% de margen por debajo esta tocando el mínimo de la variaran y es una buena forma de diseñar y ahorrar dinero. Para mi es el OC exacto para desarrollar toda la potencia y que de cada euro gastado se saque el máximo provecho. La parte negativa es que no hay margen para RT y quedo a la espera de ver la arquitectura REAL haber descubierto esto me incita a pensar que va ha haber cambios en cuanto al ancho de banda de las cache del paso de RDNA1 a 2 o quizá algún tipo de compresión de datos.
Como digo todo puede ser papel mojado si en RDNA2 han mejorado el ancho de banda de alguna cache, lo cual debería ser lo lógico, la cache L0 debería mejorarse para dar entrada al RTX en cualquiera de las 2 maquinas, o la utilización de compresión al estilo de Nvidia para dar cabida a los datos que chuparan RTX. Podría darse la inclusión de un L0 por CU en vez de cada dos CU para evitar el cuello de botella que generan al ir haciendo OC.
En mi entendimiento esto sitúa que los 12,15 Tflops de la Xbox podrán exprimirse y que los 10,21 Tflops también podrán exprimirse. La diferencia radica en que la Xbox puede tener 12,15 Tflops en coma flotante 32 al mismo tiempo. Y la PS5 tendrá 10,21 Tflops pero solo podrá genera unos 9.189 Tflops en coma flotante 32 y el resto se quedaría a la espera. O podría generar 8 Tflops en coma flotante 32 y 2,21 Tflops en coma flotante 16. Como digo todo esto es si los datos que tenemos las consolas se configuraran como RDNA 1 5700XT. No debéis tomar esto como algo malo ni un engaño, todos los juegos desde el mejor al peor tienen un mínimo un 10% de cálculos que no son en FP32 y un máximo de 50%. Una CU aunque tenga ancho de banda si esta haciendo una FLOP a 16 o con escalares no puede realizar una en FP32. Tener eso en cuenta para mi es ahorro y es el OC exacto para exprimir al máximo.
Recomiendo estar atentos a ver si hay cambios en las cache y como se alimenta RTX. Pero en principio para hacerse una idea esta bien.
En cuanto al SSD, para mi generara un cambio enorme en los videojuegos tanto a diseño como gráficamente.
Debo decir que es un SSD menor que otro en principio no debería lastrar la una a la otra y se podría optar por reducir las texturas mas alejadas en la Xbox de forma que se ajustara el ancho de banda y la diferencia seria mínima. De la misma forma que 2 Tflops. Una calcularía mas polígonos y en la otra se podrían reducir en las estructuras mas alejadas que son los menos efectivos pero se llevan los mismos cálculos.
El SSD lo que nos va a permitir es poder poner en el tiro de la camara mucha mas memoria debido a que ya no hay que cargar lo que va a pasar a 30 segundos vista. Si tardas 2-4 segundos en renovar la GDDR completa, con 2 seg PS5 o 4 segundos Xbox. Esto hará que sea la primera vez que en un tiro de cámara podamos ver entre (9-12 GB de VRAM del tirón) incluido en PC que el unico juego que aprovecha el SSD realmente es StarCitizen.
Calculo que como mas o menos vemos los modelos poligonales de los objetos con las consolas actuales 4,5-6 Tflops parecen perfectos, lo que si que ha flojeado esta generación es en texturas que se cargaba los modelos y en la cantidad de objetos distintos (VARIABILIDAD).
Debido a este nuevo ancho de banda, las texturas podrán mejorar considerablemente y a su vez la variabilidad podrá por fin entrar en escena. Es posible que sea el cambio mas emocionante desde PS2. Ya que en la variabilidad tanto de objetos como de texturas esta el realismo.
Espero haberos mejorado la tarde, y haberos pegado mi entusiasmo por la nueva GEN.
Se que algunas de mis teorías van dando bandazos de un lado al otro, pero según aprendo mas cosas van cambiando porque voy descubriendo errores en mis interpretaciones, también algunas basadas en errores o "simplificaciones" de las explicaciones de AMD en su documentación que después leyendo mas detenidamente o según avanzo en el libro voy aprendiendo cosas que pensaba que no se podían hacer abriendo camino.
Quien sabe quizá dentro de 3 días descubra algo y cambie de nuevo toda mi teoría.
Como es un tocho no espero que nadie se lo lea pero lo dejo aquí a modo de apuntes. Y creo que voy a dejar un tiempo de estudiar hardware que llevo ya una semana enfrascado en aprender como funciona y ahora que creo que he resuelto el puzzle quedo a la espera de que den mas detalles.
Un saludo.
volver a leer esto , solo en la ram la xsx le pasa por encima , con las cus tambien , refrigeracion RT dedicado , no hay debate , la cosa es que ps5 se a visto abocada a hacer overlocking a la gpu para no perder terreno y ya esta
![[qmparto]](/images/smilies/net_quemeparto.gif "Que me parto!")
Mj90 escribió:pixius escribió:Nowcry escribió:Después de mucho estudiar puedo demostrar teóricamente que la XBox Serx NO TIENE CUELLO DE BOTELLA en L1 a diferencia de lo que pasaba en RDNA1.
Ojo que es denso pero después de mucho estudiar (me aburro con el confinamiento) creo que lo he conseguido.
Voy a empezar con los cálculos de una GPU de RDNA1 para tener una referencia y porque podemos comprobar los resultados y saber si estamos bien.
Resultados según fabricante : L0 bandwith 9,76 TB/s L1 Bandwith 3.90 TB/s L2 Bandwith 1.95 TB/s
560 GB/s / 320 bits * 8 = 40 canales / 8 canales por controlador de memoria de 64 bits = 5 controladores de memoria o arrays de CU.
RDNA1 GPU Boots Clock 1905 MHz CU = 40 ancho de banda = 448 GB/s interface memoria 256 bits.
Reloj de Memoria 1750 Mhz.
Lo primero es sacar el reloj base a las que funcionan las cache, (1905 MHz / 1750 MHz) * 448 = 487.68 GB/s Esta es la velocidad de los controladores de memoria.
Ancho de banda cache L2 = 487.68 * 4 controladores de memoria = 1950.72 GB/s = lo del fabricante
Ancho de banda cache L1 = el doble que L2 = 3900 GB/s = lo del fabricante
Ancho de banda cache L0 = Reloj base * numero de cache L0 = 487.68*20 = 9750 GB/s = lo del fabricante
Ahora hago lo mismo en Xbox:
Calculamos el reloj base de las cache (1860/1750) * 560 = 595.2 GB/s
Ancho de banda cache L2 = 595.2 GB/s * 5 controladores de memoria = 2976 GB/s
Ancho de banda cache L1 = el doble que la L2 = 5952 GB/s
Ancho de banda cache L0 = 595.2 * 26 cache L0 (1 por cada 2 CU) = 15475.2 GB/s
Ahora hago lo mismo en PS5:
Calculamos el reloj base de las cache (2260/1750) * 448 = 578.56 GB/s
Ancho de banda cache L2 = 578.56 GB/s * 4 controladores de memoria = 2314.24 GB/s
Ancho de banda cache L1 = el doble que la L2 = 4628.48 GB/s
Ancho de banda cache L0 = 578.56 * 20 cache L0 = 11571.2 GB/s
(esta vez no es 1 por cada 2 CU han metido 4 arrays de 9 CU osea hay 1 CU sola en un DCU)
Ahora hago lo mismo en 2080Ti:
Calculamos el Reloj base de las cache: (1350/1750) * 616 = 475.2 GB/s
Ancho de banda cache L2 = 475.2 * 6 controladores de memoria = 2851.2 GB/s
Ancho de banda cache L1 = 475.2 * 68 SM = 32313.6 GB/s
Y ahora es cuando viene la comprobación de fuego:
El consumo teórico de una CU/SM esta basado en que tiene 64 unidades de calculo en FP32.
Desarrollo formula:
5700XT
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1860*10^6 ) *1 instruction rate / 8 Bits to Byte = 476.16 GB/s. para Xbox
Xbox SerX
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 1905*10^6 ) *1 instruction rate / 8 Bits to Byte = 487.68 GB/s. para GPU RDNA1
PS5:
(64 (stream procesor ) * cada stream procesor cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 578.56 GB/s. para GPU RDNA1
(64 (FP32 ) * cada stream procesor FP32 cogerá un paquete de 32 bits de L0 * Clock 1350*10^6 ) *1 instruction rate / 8 Bits to Byte + (64 (INT32 ) * cada stream procesor INT32 cogerá un paquete de 32 bits de L0 * Clock 2260*10^6 ) *1 instruction rate / 8 Bits to Byte = 345.6 GB/s + 345.6 GB/s = 691.2 GB/s. Después de mucho leer en el libro Whitebook de nvidia dice que han conseguido usar una compresión en la memoria del 50% y que es esencial para mantener la arquitectura centrada. 691.2/1.5 = 460.5 SOlo nos queda creernoslo. Pero por lo visto la descompresion llega hasta las Shaders Unit y Texture Units.
Whitepaper Nvidia pagina 27.
Saquemos numeros por CU:
Lcache GPU RDNA1
L2 cache 1950/40 = 48.75 GB/s
L1 cache 3900/40 = 97.5 GB/s
L0 cache 9750/40 = 244 GB/s
TOTAL 390.25 GB/s <<<<487.68 GB/s
Cuello de botella famoso Cache bandwich/
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 80%
XBOX SerX
2976/52 = 57.23 GB/s
5952 / 52 = 114.4615
15475.2 / 52 = 297.6
57.23+114.46+297.6 = 470 GB/s == 476.16 (Las diferencias de poco serán decimales o algo)
COMO ANILLO AL DEDO han hecho el OC exacto
Cache Bandwidth/FLOP CU 470 / 476.68 = 98.6% sera del 100% por los decimales.
Hago los números para PS5
2314.24/36 = 64.28 GB/s
4628.48 / 36 = 128.57
11571.2 / 36 = 321.42
57.23+114.46+297.6 = 514.26 GB/s <<< 578.65 GB/s Son las CU con mejor ancho de banda pero no podrán ejecutar ser alimentadas solo desde cache en el caso de que todas las operaciones que se hagan sean de 32 bits.
Cache Bandwidth/FLOP CU 390.15 / 487.68 = 88.98% ---> 90 % por los decimales.
2080Ti
2851.2/68 = 41.93 GB/s
32313.6 / 68 =475.2 GB/s
TOTAL = 517.13 GB/s >>> 460.5 GB/s. Sin compresion <<<<691.2.
No estoy muy seguro de mis cuentas en Nvidia . Ademas de que me faltan los tensor y RT por meterlos pero no se ni por donde empezar. Por otro lado por lo visto Nvidia tiene una Cache L1.5 y tiene cache L0 pero hay muy poca información sobre ella.
Con esto quiero decir lo siguiere:
La Xbox SerX no tiene cuello de botella en L1 que ha sido corregido al poner 5 controladores de memoria y tener un reloj mas bajo que la 5700 XT. La arquitectura esta centrada en el rendimiento teórico. A su vez han diseñado la consola robusta con 12,15 tflops de potencia FP32 y los entrega sin margenes. Lo que hará sobrar ancho de banda en la mayor parte de las ocasiones, muy interesante si finalmente hay un modo windows y permite hacerle OC, de forma que se pudiera exprimir ese extra. Este ancho de banda podría ser útil en Raytracing pero quedo a la espera de ver la arquitectura real de RDNA2. Es un producto muy solido.
En PS5 las CU son las mejor alimentadas de todas las maquinas excepto de la 2080Ti pero la arquitectura esta centrada al rendimiento económico. Esto no es malo porque hay un estudio en el Whitepaper de Nvidia en el que estudia estadisticamente cuantas operaciones de FP32 hay en el mismo ciclo.
El estudio dice que alrededor del 30% de los cálculos son escalares. Cada juego es diferente pero el margen estadístico sitúa la que varia entre [10%-50%]. Ademas de cálculos que no ocupan los 32 bits y también habrá algunos cálculos de FP16. Lo que diseñar las APU con un 10% de margen por debajo esta tocando el mínimo de la variaran y es una buena forma de diseñar y ahorrar dinero. Para mi es el OC exacto para desarrollar toda la potencia y que de cada euro gastado se saque el máximo provecho. La parte negativa es que no hay margen para RT y quedo a la espera de ver la arquitectura REAL haber descubierto esto me incita a pensar que va ha haber cambios en cuanto al ancho de banda de las cache del paso de RDNA1 a 2 o quizá algún tipo de compresión de datos.
Como digo todo puede ser papel mojado si en RDNA2 han mejorado el ancho de banda de alguna cache, lo cual debería ser lo lógico, la cache L0 debería mejorarse para dar entrada al RTX en cualquiera de las 2 maquinas, o la utilización de compresión al estilo de Nvidia para dar cabida a los datos que chuparan RTX. Podría darse la inclusión de un L0 por CU en vez de cada dos CU para evitar el cuello de botella que generan al ir haciendo OC.
En mi entendimiento esto sitúa que los 12,15 Tflops de la Xbox podrán exprimirse y que los 10,21 Tflops también podrán exprimirse. La diferencia radica en que la Xbox puede tener 12,15 Tflops en coma flotante 32 al mismo tiempo. Y la PS5 tendrá 10,21 Tflops pero solo podrá genera unos 9.189 Tflops en coma flotante 32 y el resto se quedaría a la espera. O podría generar 8 Tflops en coma flotante 32 y 2,21 Tflops en coma flotante 16. Como digo todo esto es si los datos que tenemos las consolas se configuraran como RDNA 1 5700XT. No debéis tomar esto como algo malo ni un engaño, todos los juegos desde el mejor al peor tienen un mínimo un 10% de cálculos que no son en FP32 y un máximo de 50%. Una CU aunque tenga ancho de banda si esta haciendo una FLOP a 16 o con escalares no puede realizar una en FP32. Tener eso en cuenta para mi es ahorro y es el OC exacto para exprimir al máximo.
Recomiendo estar atentos a ver si hay cambios en las cache y como se alimenta RTX. Pero en principio para hacerse una idea esta bien.
En cuanto al SSD, para mi generara un cambio enorme en los videojuegos tanto a diseño como gráficamente.
Debo decir que es un SSD menor que otro en principio no debería lastrar la una a la otra y se podría optar por reducir las texturas mas alejadas en la Xbox de forma que se ajustara el ancho de banda y la diferencia seria mínima. De la misma forma que 2 Tflops. Una calcularía mas polígonos y en la otra se podrían reducir en las estructuras mas alejadas que son los menos efectivos pero se llevan los mismos cálculos.
El SSD lo que nos va a permitir es poder poner en el tiro de la camara mucha mas memoria debido a que ya no hay que cargar lo que va a pasar a 30 segundos vista. Si tardas 2-4 segundos en renovar la GDDR completa, con 2 seg PS5 o 4 segundos Xbox. Esto hará que sea la primera vez que en un tiro de cámara podamos ver entre (9-12 GB de VRAM del tirón) incluido en PC que el unico juego que aprovecha el SSD realmente es StarCitizen.
Calculo que como mas o menos vemos los modelos poligonales de los objetos con las consolas actuales 4,5-6 Tflops parecen perfectos, lo que si que ha flojeado esta generación es en texturas que se cargaba los modelos y en la cantidad de objetos distintos (VARIABILIDAD).
Debido a este nuevo ancho de banda, las texturas podrán mejorar considerablemente y a su vez la variabilidad podrá por fin entrar en escena. Es posible que sea el cambio mas emocionante desde PS2. Ya que en la variabilidad tanto de objetos como de texturas esta el realismo.
Espero haberos mejorado la tarde, y haberos pegado mi entusiasmo por la nueva GEN.
Se que algunas de mis teorías van dando bandazos de un lado al otro, pero según aprendo mas cosas van cambiando porque voy descubriendo errores en mis interpretaciones, también algunas basadas en errores o "simplificaciones" de las explicaciones de AMD en su documentación que después leyendo mas detenidamente o según avanzo en el libro voy aprendiendo cosas que pensaba que no se podían hacer abriendo camino.
Quien sabe quizá dentro de 3 días descubra algo y cambie de nuevo toda mi teoría.
Como es un tocho no espero que nadie se lo lea pero lo dejo aquí a modo de apuntes. Y creo que voy a dejar un tiempo de estudiar hardware que llevo ya una semana enfrascado en aprender como funciona y ahora que creo que he resuelto el puzzle quedo a la espera de que den mas detalles.
Un saludo.
volver a leer esto , solo en la ram la xsx le pasa por encima , con las cus tambien , refrigeracion RT dedicado , no hay debate , la cosa es que ps5 se a visto abocada a hacer overlocking a la gpu para no perder terreno y ya esta
Claro al día siguiente de mostrar Microsoft el hardware de series X, a Sony se le ocurrió rápido lo del tema de poner frecuencia variable.
dunkam82 escribió:silenius escribió:manmartin escribió:@silenius esos cálculos parten de que las dos tienen 64 rops,no? Se rumorea que series ese tiene 80 rops
Si, calculos con la presuncion de que son 64 rops. Lo que de que se rumorea, ya dije que creo que hicieron las cuentas de la lechera y por eso salen 80. Si no se ha modificado el estandar de 16 rops por shader array no llevará mas de 64. Pero como todavia no hemos visto ningun diagrama de las gpu de ninguna ni Ms ni Sony sueltan prenda pues es todo especular. No sabemos hasta que punto han personalizado el diseño o cuanto han modificado.
Mira aquí no especulan aquí lo dan como dato que Series X tiene 80 ROPS lo cual tiene sentido con el Die Size más grande, están todas las specs completas o al menos bastantes del SOC.ENLACEThe Scarlett graphics processor is a large chip with a die area of 360 mm² and 14,750 million transistors. It features 3328 shading units, 208 texture mapping units, and 80 ROPs. AMD includes 10 GB GDDR6 memory, which are connected using a 320-bit memory interface. The GPU is operating at a frequency of 1825 MHz, memory is running at 1750 MHz.
Sabiendo que tiene 80ROPS ¿cómo quedarían las cuentas esas que se hacían antes?
oestrimnio escribió:@Mj90
Hace semanas que quedó claro de que no se puede decir que la XSX tiene 80 ROPs (16 más que la pley) por no ser oficial. Eso si, decir que tienen la misma cantidad si se puede, o incluso que la pley tiene 64 como mínimo; y por supuesto SIEMPRE a 2233 Mhz, lo de la preposición "hasta" algunos no la entienden muy bien.
Aquí cada uno hace las cuentas de la lechera como le sale de los hue###.
oestrimnio escribió:@Mj90
Con el debido respeto, hay que ser en esta vida un poco más críticos y escépticos, no tragarse cualquier tontería; pensar, comparar e intentar llegar a conclusiones uno solo sin dejar llevarse por la manito de cualquiera. Nadie con dos dedos de frente se cree que entre ambas GPUs (compartiendo tanto) pueda haber 400 Mhz de diferencia; eso además de falso es un disparate.
Algunos se deben de creer que la de M$ lleva una GPU "al ralentí" y que se han gastado lo indecible en crear una consola mucho más potente para después hacerle un underclock. Que el factor de forma y todo el sobrecoste que supone su refrigeración es para que te sirva de nevera... muy lógico.
La pley va a ser una fantástica consola de 8,5/9 TFs, y lo demás es un quiero y no puedo que hace un flaco favor a la marca Sony, que ya tiene suficiente solera como para no necesitar de mentiras burdas que solo se las tragan los fanboys más ignorantes. Que tiren de catálogo (que deberían ir sobrados) y se dejen de tonterías.
xhakarr escribió:Tmac_1 escribió:Vamos, que dirán precios en agosto en el reveal de la Series S.
Cómo Sony siga la costumbre de esperar a que Microsoft de precio nos plantamos en septiembre.
El hasta ahora fiable Jeff Grubb dice que lo de Iniciative se lo guardan para más adelante.
La guerra fria del precio, alguien tendra que decirlo primero, se tienen que abrir reservas ya...
oestrimnio escribió:@Mj90
Con el debido respeto, hay que ser en esta vida un poco más críticos y escépticos, no tragarse cualquier tontería; pensar, comparar e intentar llegar a conclusiones uno solo sin dejar llevarse por la manito de cualquiera. Nadie con dos dedos de frente se cree que entre ambas GPUs (compartiendo tanto) pueda haber 400 Mhz de diferencia; eso además de falso es un disparate.
Algunos se deben de creer que la de M$ lleva una GPU "al ralentí" y que se han gastado lo indecible en crear una consola mucho más potente para después hacerle un underclock. Que el factor de forma y todo el sobrecoste que supone su refrigeración es para que te sirva de nevera... muy lógico.
La pley va a ser una fantástica consola de 8,5/9 TFs, y lo demás es un quiero y no puedo que hace un flaco favor a la marca Sony, que ya tiene suficiente solera como para no necesitar de mentiras burdas que solo se las tragan los fanboys más ignorantes. Que tiren de catálogo (que deberían ir sobrados) y se dejen de tonterías.
AMD Ryzen 7 PRO 4750G/GE APU
The AMD Ryzen 7 4750G is the flagship variant of the Ryzen 4000 Renoir APU family. It features 8 cores, 16 threads, 4 MB of L2 and 8 MB of L3 cache for a total of 12 MB cache. This is lower than the 32 MB of L3 cache which the 8 core Ryzen 7 3800X features but as stated before, this is mainly due to the monolithic nature of the chip which relies on a single package rather than the chiplet based design on the Matisse series desktop processors.
The CPU features a base clock of 3.60 GHz and a boost clock of 4.45 GHz which matches the earlier specifications leak. The CPU operates with a 65W TDP and is compatible with the AM4 socket. The graphics side features the enhanced 7nm Vega GPU which comes with 8 CUs to form 512 cores. Its clocked at 2100 MHz on the GPU side which makes it one of the fastest clocked integrated graphics chip. The 35W variant on the other hand features clock speeds of 3.1 GHz base and 4.35 GHz boost.
aaalexxx escribió:Este año nos plantamos en Septiembre y alguna de las dos todavía no habrá dicho precio ni juegos de lanzamiento, parece que prisa no tienen.
aaalexxx escribió:xhakarr escribió:Tmac_1 escribió:Vamos, que dirán precios en agosto en el reveal de la Series S.
Cómo Sony siga la costumbre de esperar a que Microsoft de precio nos plantamos en septiembre.
El hasta ahora fiable Jeff Grubb dice que lo de Iniciative se lo guardan para más adelante.
La guerra fria del precio, alguien tendra que decirlo primero, se tienen que abrir reservas ya...
Este año nos plantamos en Septiembre y alguna de las dos todavía no habrá dicho precio ni juegos de lanzamiento, parece que prisa no tienen.
pers46 escribió:@silenius
Lo de esas frecuencias se comentó hace un mes, más o menos. Yo creo que hay claros indicios de que se pueden alcanzar frecuencias superiores a Ps5.
pers46 escribió:@silenius
Pues ahora estoy en el móvil pero recuerdo comentar una filtración sobre esto, y lo recuerdo porque se puso en duda por tener 6 u 8 CUs.
Esto fue: viewtopic.php?p=1749513540
aaalexxx escribió:@lichis Pues a mi no me quedó claro que sacará PS5 de lanzamiento, el Spider-Man 1.5 y ¿algo más?
silenius escribió:dunkam82 escribió:
1º Ni siquiera se ha teniendo en cuenta el número de CUs, cosa que es una cagada. Yo no soy ingeniero ni nada parecido pero si se están haciendo unas operaciones en las que estás multiplicando por la frecuencias de reloj, tendrás que multiplicar también por el número de CU´s que ejecutan esas frecuencias, si no lo haces es asumir que ambas tienen el mismo número de CUs y no es así cuando una tiene 36 y la otra tiene 52.
Claro que así salen en esas cuentas la PS5 como ganadora, ahora mete el número de CUs en la ecuación a ver qué pasa.
2º Se está dando por hecho en esas "cuentas" que la frecuencia de la GPU va a ir siempre al máximo, porque claro es lo que interesa para que te salga PS5 vencedora, pero te recuerdo que la PS5 tiene frecuencias variables y además tiene que ir distribuyendo la potencia entre la CPU y la GPU por lo que ni de coña va a ir siempre al máximo.
Entre otras cosas porque si han hecho lo de las frecuencias variables es por problemas de temperatura, si no fuese así, Sony hubiera puesto a trabajar a tope de forma fija la GPU y la CPU al máximo, como ha hecho Microsoft con Series X, y no hubiera hecho esa chapuza.
3º Se está dando por hecho que la subida de las frecuencias de reloj tienen un incremento lineal de la potencia cuando tampoco es así, hay por ahí varios análisis (uno de ellos creo que de Digital Foundry) en el que prueban con una 5700XT que es RDNA 1 (lo más cercano que tenemos al 2) y se va viendo como llegado a cierto punto el aumento de la velocidad no repercute en su equivalente en potencia/rendimiento.
4º Se está dando por hecho para el tema del Ray Tracing que la mayor frecuencia de reloj compensn la diferencia del número de CUs, pero lo cierto es que para el cálculo de Ray Tracing la ganancia con mayor número de CUs es mucho mayor que por frecuencias más altas .... y Series X tiene un 44% más de CU´s que PS5.
En fin creo que después de estos 4 puntos queda claro que todas esas cuentas y cálculos, sea quien sea que los haya hecho no sirven para NADA.
Para esos calculos no se necesitan el numero de CU para nada
El rasterizador es capad de procesar 1 triangulo por ciclo, y hay un rasterizador por shader array, por lo que:
PS5:
4 x 2.23 GHz ~ 8.92 mil millones de triángulos por segundo
XSX:
6 x 1.825 GHz - 10.9 mil millones de triángulos por segundo
= XSX:22.75% de ventaja
La tasa de eliminación de triángulos es dos triángulos rasterizados por ciclo por primitive unit, de las cuales hay 1 por cada shader array.
PS5:
2 (triangulos) x 4 (primitive unit) x 2.23 GHz - 17.84 billones de triángulos por segundo
XSX:
2 (triangulos) x 6 (primitive unit) 1.825 GHz - 21.9 billones de triángulos por segundo
=XSX:22.75% de ventaja
En el caso de la tasa de relleno de píxeles (pixel fill-rate), cada render backend (RB) procesa 4 pixeles por ciclo, con cuatro unidades RB por shader array, por lo tanto:
PS5:
16 RB (4 RB's por 4 shader arrays) x 4 (pixeles por ciclo) x 2.23 GHz - 142.72 mil millones de píxeles por segundo
XSX:
24 RB (4 RB's por 6 shader arrays) x 4 (pixeles por ciclo) x 1.825 GHz - 175.20 mil millones de píxeles por segundo
= XSX: 22.75% de ventaja
(sacado de neogaf)
![[oki]](/images/smilies/net_thumbsup.gif "Ok!")




