.png)
"In the IoMmu model each process has a single virtual address space that is shared between the CPU and graphics processing unit (GPU) and is managed by the OS memory manager.
To access memory, the GPU sends a data request to a compliant IoMmu. The request includes a shared virtual address and a process address space identifier (PASID). The IoMmu unit performs the address translation using the shared page table."
https://msdn.microsoft.com/en-us/library/windows/hardware/dn894176(v=vs.85).aspxReason for IOMMU & new OS WDDM"For example, the discrete chip arrangement forces system and software architects to utilize chip to chip interfaces for each processor to access memory. While these external interfaces (e.g., chip to chip) negatively affect memory latency and power consumption for cooperating heterogeneous processors, the separate memory systems (i.e., separate address spaces) and driver managed shared memory create overhead that becomes unacceptable for fine grain offload.
Both the discrete and single chip arrangements can limit the types of commands that can be sent to the GPU for execution. By way of example, computational commands (e.g., physics or artificial intelligence commands) often should not be sent to the GPU for execution. This performance-based limitation exists because the CPU may relatively quickly require the results of the operations performed by these computational commands. However, because of the high overhead of dispatching work to the GPU in current systems and the fact that these commands may have to wait in line for other previously-issued commands to be executed first, the latency incurred by sending computational commands to the GPU is often unacceptable.
Given that a traditional GPU may not efficiently execute some computational commands, the commands must then be executed within the CPU. Having to execute the commands on the CPU increases the processing burden on the CPU and can hamper overall system performance.
Although GPUs provide excellent opportunities for computational offloading, traditional GPUs may not be suitable for system-software-driven process management that is desired for efficient operation in some multi-processor environments. These limitations can create several problems.
For example, since processes cannot be efficiently identified and/or preempted, a rogue process can occupy the GPU hardware for arbitrary amounts of time. In other cases, the ability to context switch off the hardware is severely constrained—occurring at very coarse granularity and only at a very limited set of points in a program's execution. This constraint exists because saving the necessary architectural and microarchitectural states for restoring and resuming a process is not supported. Lack of support for precise exceptions prevents a faulted job from being context switched out and restored at a later point, resulting in lower hardware usage as the faulted threads occupy hardware resources and sit idle during fault handling."
http://www.freepatentsonline.com/8578129.html 

 , vamos que se sirven a diferentes calidades según la conexión de que lo ve.
, vamos que se sirven a diferentes calidades según la conexión de que lo ve. ![[chulito]](/images/smilies/nuevos/sonrisa_ani2.gif "risa con gafas")
![[+furioso]](/images/smilies/nuevos/furioso.gif "muy furioso")

![[360º]](/images/smilies/nuevos/vueltas.gif "como la niña del exorcista")

 ) que sólo ganarán CPU. Es que si no sería demasiado
) que sólo ganarán CPU. Es que si no sería demasiado ![[+risas]](/images/smilies/nuevos/risa_ani3.gif "más risas")
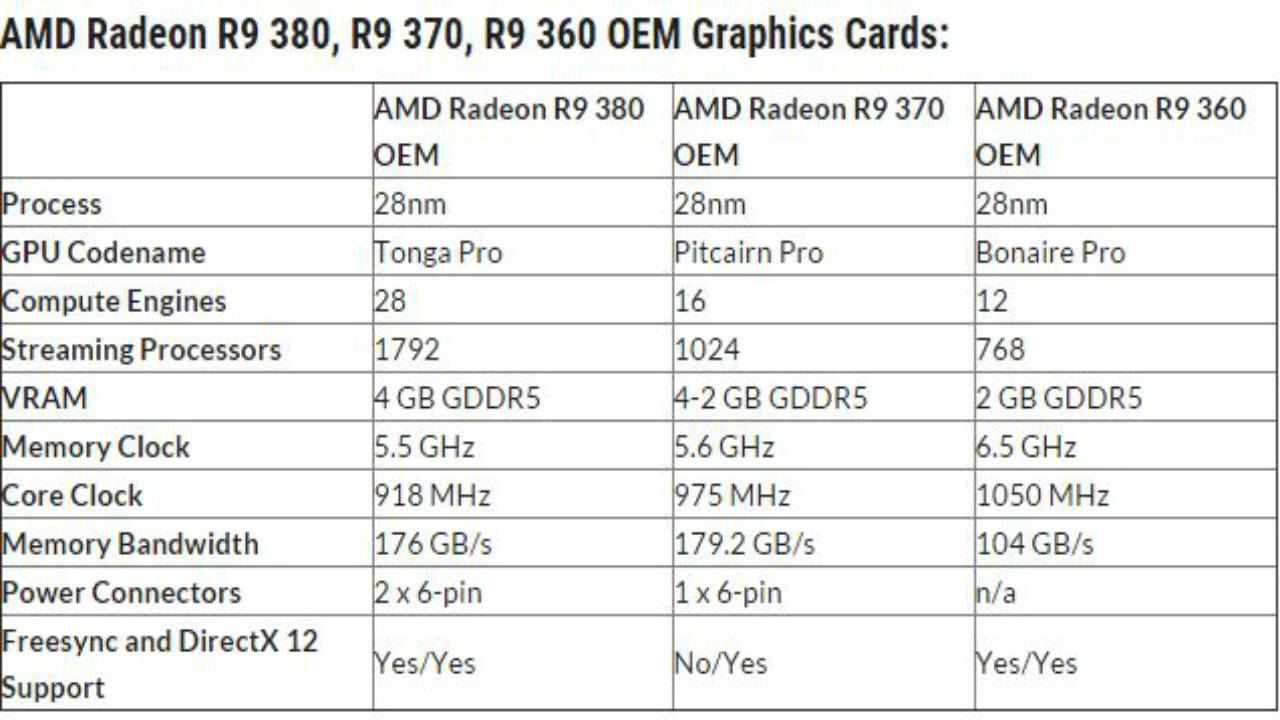
![[oki]](/images/smilies/net_thumbsup.gif "Ok!")
![[carcajad]](/images/smilies/nuevos/risa_ani2.gif "carcajada")
![[sonrisa]](/images/smilies/nuevos/risa_ani1.gif "sonrisa")